Лабораторна робота 1
Вказівники на функції та заголовні файли
1 Завдання на лабораторну роботу
1.1 Виведення таблиці значень функції
Створити окрему одиницю трансляції, в якій реалізувати функцію виведення таблиці значень певної функції з визначеним кроком. Параметри функції – початок, кінець інтервалу, крок і вказівник на функцію, значення якої будуть виведені в таблиці. У заголовному файлі описати тип вказівника на функцію і прототип функції виведення таблиці значень. У файлі реалізації визначити функцію виведення таблиці значень.
В іншій одиниці трансляції розташувати функції, для яких слід вивести значення у таблиці, а також функцію
main(), в якій здійснюється виведення таблиць значень не менш ніж двох різних функцій.
Одна з функцій для тестування – функція, визначена в індивідуальному завданні першої
лабораторної роботи попереднього семестру та реалізована в завданні четвертої
лабораторної роботи попереднього
семестру.
1.2 Індивідуальне завдання
Написати програму, яка реалізує перебір значень на визначеному інтервалі з певним кроком з метою пошуку
деякого значення відповідно до індивідуального завдання, наведеного в таблиці. Необхідне значення може
бути знайдено шляхом отримання проміжних значень функції (або першої / другої похідної). Слід
використати вказівник на функцію, для якого визначити
Сирцевий код повинен бути розділений на дві одиниці трансляції. Перша одиниця трансляції буде
представлена заголовним файлом і файлом реалізації. Визначення main(), повинні бути розташовані в іншій одиниці трансляції.
| Номер варіанту (номер студента у списку) |
Правило пошуку: |
|---|---|
|
1, 17
|
Максимальне значення другої похідної функції |
|
2, 18
|
Мінімальне значення першої похідної функції |
|
3, 19
|
Найменший корінь рівняння, для якого визначена ліва частина |
|
4, 20
|
Найбільший корінь рівняння, для якого визначена ліва частина |
|
5, 21
|
Сума мінімального і максимального значень функції |
|
6, 22
|
Добуток мінімального і максимального значень функції |
|
7, 23
|
Кількість коренів рівняння, для якого визначена ліва частина |
|
8, 24
|
Найменший корінь другої похідної функції |
|
9, 25
|
Мінімальне значення другої похідної функції |
|
10, 26
|
Максимальне значення першої похідної функції |
|
11, 27
|
Найменший корінь першої похідної функції |
|
12, 28
|
Найбільший корінь першої похідної функції |
|
13, 29
|
Найбільший корінь другої похідної функції |
|
14, 30 |
Сума мінімального і максимального значень функції |
|
15, 31
|
Визначений інтеграл функції на інтервалі методом прямокутників |
|
16, 32
|
Визначений інтеграл функції на інтервалі методом трапецій |
Слід перевірити працездатність програми не менш ніж на двох довільних функціях. Одна з функцій може бути стандартною.
Корінь – це значення аргументу, в якій функція повертає нуль.
Примітка: Для обчислення першої похідної y(x) можна використати таку формулу:
Де Δx деяке невеличке значення, наприклад 0.0000001.
1.3 Робота з масивом вказівників на функції
В окремому просторі імен описати синонім типу вказівника на функцію, яка приймає два аргументи типу
Поза створеним простором імен визначити функцію, яка приймає два аргументи типу
У функції main() створити масив вказівників на функції описаного раніше типу. В масиві розташувати
вказівники на стандартні функції заголовного файлу cmath, які отримують два аргументи, а також вказівник на раніше
створену функцію обчислення суми других степенів. Прочитати з клавіатури значення двох аргументів і в циклі вивести
аргументи й функцію для всіх вказівників на функції з масиву.
Рекомендовані функції заголовного файлу cmath, які отримують два аргументи типу
pow()– довільний степінь числа;hypot()– величина гіпотенузи для двох вказаних катетів прямокутного трикутника;fmax()– максимальне з двох значень;fmin()– мінімальне з двох значень;
Продемонструвати різні способи підключення елементів простору імен.
2 Методичні вказівки
2.1 Мова C++ і її версії
C++ це високорівнева універсальна мова програмування, яка одночасно підтримує декілька парадигм програмування:
- Імперативне програмування – парадигма програмування, яка передбачає представлення програми як послідовності інструкцій. Ці інструкції описують, як система повинна виконувати певні дії. Розробник явно описує кроки, які потрібно виконати для досягнення певної мети. Для реалізації парадигми імперативного програмування C++ надає низку синтаксичних конструкцій, таких як твердження-вирази, умовні конструкції, цикли й переходи на мітку.
- Процедурне програмування – парадигма програмування, в якій програма складається з набору процедур або функцій. Кожна функція має фіксований набір вихідних параметрів та результат. Процедури (функції) працюють зі своїм набором локальних змінних. Одночасно підтримується можливість використання глобальних змінних, які визначають стан програми. Мова C++ надає всі необхідні засоби для реалізації процедурного програмування.
- Модульне програмування – це підхід до розробки програмного забезпечення, в якому програма розбивається на окремі незалежні фізично або логічно відокремлені частини. Кожен модуль надає конкретний набір типів і операцій.У C++ реалізовано фізичне групування коду через механізм заголовних файлів і файлів реалізації й логічне групування коду через використання просторів імен (namespaces). Починаючи з версії C++20 додано концепцію модулів (modules), які забезпечують одночасно фізичне й логічне групування коду.
- Об'єктно-орієнтоване програмування (об'єктно-орієнтоване програмування, ООП) – це парадигма програмування, в якій програма представлена набором об'єктів, що взаємодіють між собою. Об'єкти характеризуються станом (поля) і поведінкою (методи). Клас є описом типу об'єкта. C++ надає потужні засоби створення користувацьких типів – класів і структур. Додатково можна створювати переліки й об'єднання.
- Узагальнене програмування – це парадигма програмування, яка дозволяє створювати функції та класи, які можуть підтримувати незалежну роботу з різними типами даних без прив'язки до конкретного типу. Узагальнене програмування реалізоване в C++ через механізм шаблонів (templates).
- Функційне програмування – це парадигма програмування, в якій основним будівельним блоком є функція. Робота полягає в маніпуляції функціями: рекурсія, зворотний виклик тощо. Починаючи з версії C++11 існує спеціальний різновид функційних об'єктів – лямбда-вирази.
Завдання цього курсу – опанувати засоби модульного, об'єктно-орієнтованого, узагальненого та функційного програмування, які надає мова C++. Крім того, буде розглянуто засоби Стандартної бібліотеки шаблонів (STL).
Б'ярн Страуструп почав роботу над мовою, схожою на C, але такою, яка підтримує об'єктно-орієнтоване програмування, з 1979 року. Назва C++ з'явилася у 1983 році. У 1985 році була опублікована перша версія мови C++.
Друга версія мови виникла у 1989 році. Перша версія мови була істотно розширена. У 1990 році опубліковано поточний стан мови. Опублікований опис мови фактично став базою для майбутнього стандарту мови C++.
Як і більшість сучасних мов, C++ стандартизована. Існує декілька версій міжнародного стандарту мови C++:
- У 1998 році був випущений стандарт C++98 (третя версія мови). Стандарт був затверджений міжнародним консорціумом Object Management Group (OMG), а у 2003 році було випущено незначне оновлення (C++03). Окрім усіх раніше запропонованих мовних конструкцій, до стандарту було включено Стандартну бібліотеку шаблонів (STL), яка стала частиною Стандартної бібліотеки С++. Для реалізації модульності була додана концепція простору імен (namespace).
- У 2011 році було випущено стандарт C++11, який містив істотні розширення мови (новий синтаксис циклів, лямбда-вирази тощо) та Стандартної бібліотеки. Незначні оновлення були зроблені у версії C++14. У C++17 було введено різні нові доповнення.
- Стандарт C++20 було схвалено 4 вересня 2020 року та офіційно опубліковано 15 грудня 2020 року. У стандарті, зокрема, вводиться механізм модулів.
- Стандарт мови C++23 було схвалено в лютому 2020 року та офіційно опубліковано в жовтні 2024 року.
2.2 Інтегровані середовища для розробки програм мовою C++
2.2.1 Загальний огляд
Від початку створення програм мовою C++ передбачало окрему підготовку сирцевого коду за допомогою текстового редактора, запуск у командному рядку компілятора, лінкера, і безпосередньо програми для зневадження й тестування. Перший компілятор C++, Cfront, був розроблений Б'ярном Страуструпом у 1983 році.
З метою підвищення продуктивності роботи програмістів створюються інтегровані середовища розробки. Інтегроване середовище розробки (IDE) – це програмні засоби, які надають розробникам усі необхідні інструменти для розробки програмного забезпечення, інтегровані в одному застосунку. Основні складники IDE:
- текстовий редактор,
- компілятор, засоби зневадження,
- засоби збирання проєктів,
- засоби керування версіями,
- засоби автоматизації завдань.
Окрім засобів від Microsoft в різні часи були популярними різні IDE для розробки програм мовою C++. Наприклад:
- Borland C++Builder – інтегроване середовище розробки, створене фірмою Borland International. IDE призначене в першу чергу для швидкої розробки застосунків (RAD, Rapid Application Development). Окрім повної підтримки синтаксису C++, розробникам надавалась бібліотека візуальних компонентів для створення застосунків Windows.
- Dev-C++ – IDE для розробки програм на C++ для платформи Windows. Середовище надавало основні можливості, такі як текстовий редактор, компілятор та засоби для налагодження.
- Eclipse CDT. Eclipse – популярне інтегроване середовище розробки для різних мов програмування, в першу чергу Java. За допомогою плагіну C/C++ Development Tooling (CDT), Eclipse надавав зручні засоби для розробки програм на C++.
- Code::Blocks – відкрите і безплатне IDE для розробки програм на C++, яке надає зручний інтерфейс користувача та базові можливості для роботи з проєктами на C++.
- Qt Creator: Qt Creator – це інтегроване середовище розробки, спеціально призначене для розробки програм з використанням бібліотеки Qt. Воно надавало зручні засоби для роботи з Qt та мовою програмування C++.
- CLion – IDE від JetBrains, яке включає інтелектуальний редактор коду, засоби налагодження, підтримку систем керування версіями та інші функції, спрямовані на підвищення продуктивності розробника.
- Xcode є основним середовищем розробки для macOS і має підтримку розробки на C++ разом з іншими мовами програмування.
Для розробки програм мовою C++ можна також пристосувати Microsoft Visual Studio Code (VS Code) – безплатний кросплатформний текстовий редактор із широкими можливостями для розробки програмного забезпечення. Він підтримує велику кількість мов програмування, серед яких і C++, і надає інструменти для налагодження, підсвічування синтаксису, автозаповнення коду, роботи з системою контролю версій (Git) та багато іншого. Оскільки VS Code – це не середовище програмування, а редактор коду, для створення і зневадження програм мовою C++ окрім безпосередньо VS Code необхідно встановити засоби компіляції та інші необхідні утиліти. Microsoft Visual Studio Code не слід плутати з Microsoft Visual Studio.
Microsoft Visual C++ – це інтегроване середовище розробки (IDE) та компілятор для мови програмування C++. Нижче наведені деякі з версій Visual C++:
- Visual C++ 1.0 (1993): Це була перша версія Visual C++, яка вийшла в 1993 році. Вона включала середовище розробки та компілятор для мови програмування C++.
- Visual C++ 2.0 (1994): Ця версія вийшла в 1994 році й включала підтримку Windows 95, новий компілятор C++ і покращене середовище розробки.
- Visual C++ 4.0 (1995): Версія 4.0 була випущена в 1995 році разом з випуском Windows 95. Вона включала підтримку 32-бітових застосунків для Windows, ActiveX-компонентів і COM-об'єктів.
Подальші версії входили в склад інтегрованого середовища Microsoft Visual Studio.
2.2.2 Особливості та версії MS Visual Studio
Microsoft Visual Studio - це інтегроване середовище розробки (IDE), яке підтримує різні мови програмування, включаючи C++, C#, Visual Basic .NET, F# та інші. Нижче наведені ранні версії Microsoft Visual Studio:
- Visual Studio 97: Це була перша версія Visual Studio, яка включала інтегроване середовище розробки для платформи Win32.
- Visual Studio 6.0: Вийшла в 1998 році та містила середовище розробки для різних мов програмування, таких як Visual Basic 6.0, Visual C++, Visual FoxPro та інші.
- Visual Studio .NET 2002: Ця версія вийшла разом з платформою .NET і включала підтримку для мов програмування, які працюють на CLR (Common Language Runtime), таких як C#, Visual Basic .NET та C++/CLI.
Далі версії виходили в середньому один раз на два роки. Остання версія Visual Studio 2026 надає можливості використання штучного інтелекту. Покращені можливості інтегрованого середовища, реалізовані засоби роботи з останніми версіями мов програмування.
Традиційно версії Visual Studio підтримують новітні версії C++.
2.3 Псевдоніми типів
C++ дозволяє створити псевдонім для імені типу, який існує, використовуючи ключове слово
В результаті створюється синонім для типу. Важливо відрізняти створення
синоніма від створення нового типу (визначення структур, переліків і класів). Визначення синоніма
починається з ключового слова
typedef unsigned long int Integer;typedef int IntArray[15];
створює нове ім'я Integer, яке можна використовувати в будь-якому місці замість IntArray може бути використаний для визначення масиву з
15 цілих значень:
Integer c;int f(Integer k); IntArray a;// int a[15];
Визначення
Для синонімів типів можна використовувати імена, які починаються з великої літери, щоб було видно, що це не змінна
і не стандартний тип. Але в цьому випадку імена можна переплутати з іменами користувацьких типів (структур, переліків,
класів). Альтернативне правило визначення імен псевдонімів _t, наприклад:
typedef unsigned int integer_t;typedef int array15_t[15];
Далі використовуватимуться обидва варіанти.
Синоніми типів дозволяють приховати деталі реалізації, які можуть змінитися. Наприклад, якщо під час подальшої
розробки з'ясується, що замість беззнакового довгого цілого слід вживати знакове, достатньо змінити визначення
typedef signed long int Integer;
Після перекомпіляції ім'я Integer у програмі буде інтерпретовано як довге знакове ціле.
Визначення
unsigned long long int ** a1[20];// unsigned long long int ** a2[20];
В такому випадку доцільно створити визначення
typedef unsigned long long int ** arr[20];
Тепер змінні можна визначити так:
arr a1;// arr a2;
Слід пам'ятати, що такі визначення іноді знижують читабельність коду.
Іноді синоніми стандартних типів визначають в бібліотеках. Ці імена дозволяють приховати деталі
реалізації, які можуть змінитися. Крім того, використання синонімів дозволяє
вказати на зв'язок змінної, параметру або функції з засобами деякої бібліотеки. Наприклад, ім'я size_t визначено
в Стандартній бібліотеці C++:
typedef unsigned long size_t;
Примітка: залежно від платформи синонім типу size_t може бути визначено інакше, наприклад:
typedef unsigned long long size_t;
Якщо змінна index створена для роботи з колекціями Стандартної бібліотеки, для її опису краще використовувати size_t:
size_t index;
Популярний тип string Стандартної бібліотеки теж є синонімом певного шаблонного типу.
Починаючи з версії C++11 до мови додано альтернативний синтаксис створення псевдонімів типів – конструкцію
using. Наприклад, замість визначення
typedef int Integer;
можна запропонувати таку конструкцію:
using Integer =int ;
Можна вказати такі переваги використання using:
- краща читабельність;
- більш логічна синтаксична послідовність (ім'я завжди ліворуч);
- підтримка псевдонімів шаблонів.
Шаблони в C++ будуть розглянуті пізніше.
2.4 Вказівники на функції
2.4.1 Опис вказівників на функції
Вказівник на функцію – це адреса, де зберігається скомпільований код цієї функції, тобто адреса, за якою передається управління, коли ця функція викликається. Так само як ім'я масиву є константним вказівником на перший елемент масиву, ім'я функції можна розглядати як константний вказівник на функцію. Можна оголосити змінну – вказівник, який вказує на функцію, і викликати функцію за допомогою цього вказівника.
Вказівник на функцію повинен вказувати на функцію з відповідним типом результату і сигнатурою. У визначенні
int (*funcPtr)(double );
funcPtr оголошується вказівник, який вказує на функцію, що приймає параметр з рухомою
комою і повертає ціле значення. Дужки навколо *funcPtr необхідні. Без першої пари дужок це
був би прототип функції, яка приймає
Вказівнику на функцію можна присвоїти адресу певної функції шляхом присвоєння імені функції без дужок. Тепер вказівник можна використовувати так само як ім'я функції. Вказівник на функцію повинен бути узгоджений з функцією за типом результату і сигнатурою. Наприклад:
int round(double x){ return x + 0.5; }int main() {int (* funcPtr)(double );double y; cin >> y; funcPtr= round; cout << funcPtr(y);return 0; }
Вказівник на функцію не потрібно розіменовувати, хоча це можна зробити. Тому, якщо pFunc є
вказівником на функцію, в який записано адресу реальної функції, можна викликати цю функцію
безпосередньо
pFunc(x);
або
(*pFunc)(x);
Обидві форми ідентичні.
Для створення більш відповідних імен типів вказівників на функції часто використовують визначення
typedef int (*FuncType)(int ); FuncType pf;
2.4.2 Використання вказівників на функції
Можна створити масив указівників на функції. Наприклад, можна створити таку функцію:
double f(double x) {return 1 / x; }
Потім можна створити масив указівників на функції та значення цієї функції, а також деяких стандартних функцій для аргументу 2 можна вивести в циклі:
double (*func[])(double ) = { f, sin, cos, exp };for (int i = 0; i < 4 ; i++) { cout << func[i](2) << endl; }
Використання вказівників на функції може підвищити ефективність розв'язання задач, в яких необхідно вибирати з набору фіксованих функцій. Наприклад, необхідно реалізувати програму, в якій користувач уводить початок і кінець інтервалу, а також крок, потім вибирає функцію (вводить її номер) і отримує таблицю значень аргументів і функції. Без використання вказівників на функції код програми може буде таким:
#include <iostream> #include <cmath>int main() { std::system("chcp 65001 > nul");double from, to, step; std::cout << "Уведіть початок, кінець і крок для таблиці значень функції:"; std::cin >> from >> to >> step; std::cout << "Уведіть номер функції (1 - sin, 2 - cos, 3 - sqrt):";int index; std::cin >> index;if (index < 1 || index > 3) {return -1; }for (double x = from; x <= to; x += step) {double y = 0;switch (index) {case 1: y = std::sin(x);break ;case 2: y = std::cos(x);break ;case 3: y = std::sqrt(x); } std::cout << x << "\t" << y << std::endl; }return 0; }
Примітка. Для коректного виведення на консоль українського тексту в попередніх версіях Visual Studio необхідно
було користуватися командою chcp 1251 > nul. Починаючи з версії Visual Studio 2026 цю команду слід заминти на
chcp 65001 > nul в зв'язку з орієнтацією середовища на виконистання кодової таблиці Unicode.
Недоліком реалізації є вибір функції на кожному кроці циклу. Це, зокрема, уповільнює роботу програми. Можна здійснити визначення функції до початку циклу, скориставшись указівником на функцію:
#include <iostream> #include <cmath>int main() { std::system("chcp 65001 > nul");double from, to, step; std::cout << "Уведіть початок, кінець і крок для таблиці значень функції:"; std::cin >> from >> to >> step; std::cout << "Уведіть номер функції (1 - sin, 2 - cos, 3 - sqrt):";int index; std::cin >> index;if (index < 1 || index > 3) {return -1; }// Для усталеної реалізації використовуємо лямбда-вираз: double (*f)(double ) = [](double ) {return 0.0; };switch (index) {case 1: f = std::sin;break ;case 2: f = std::cos;break ;case 3: f = std::sqrt; }for (double x = from; x <= to; x += step) { std::cout << x << "\t" << f(x) << std::endl; }return 0; }
Можна також скористатися масивом функцій:
#include <iostream> #include <cmath>int main() { std::system("chcp 65001 > nul");double from, to, step; std::cout << "Уведіть початок, кінець і крок для таблиці значень функції:"; std::cin >> from >> to >> step; std::cout << "Уведіть номер функції (1 - sin, 2 - cos, 3 - sqrt):";int index; std::cin >> index;if (index < 1 || index > 3) {return -1; }const int n = 3;double (*f[n])(double ) = { std::sin, std::cos, std::sqrt };for (double x = from; x <= to; x += step) { std::cout << x << "\t" << f[index - 1](x) << std::endl; }return 0; }
2.4.3 Зворотний виклик
Вказівники на функції часто використовують як типи параметрів функцій. Механізм зворотного виклику (callback) передбачає визначення певної функції, виклик якої здійснюється не безпосередньо в тій частині коду, де вона визначена, а з іншої частини коду, куди можна надіслати вказівник на цю функцію, наприклад, як параметр іншої функції.
Наприклад, є певний універсальний алгоритм, який для своєї роботи вимагає здійснення викликів іншої функції. Функція в цьому випадку виступає як деяка інформація поруч з числовими та іншими аргументами. Це можуть бути різні задачі, наприклад:
- реалізація універсального алгоритму розв'язання рівняння
- знаходження максимумів і мінімумів
- обчислення похідної
- обчислення визначеного інтеграла
- знаходження точок перегину
- обробка події, пов'язаної з діями користувача тощо.
Вказівник на функції в першу чергу використовують саме для реалізації цього механізму.
Наприклад, деяка функція (алгоритм) вимагає іншу функцію як параметр:
void someAlgorithm(void (*f)(double )) {double z;//... f(z);//... }
В іншій частині коду створюємо необхідну функцію та передаємо її адресу як параметр:
void g(double x) {//... }int main() {//... someAlgorithm(g);//... }
Приклад 3.1 ілюструє використання механізму callback для розв'язання рівняння методом ділення відрізка навпіл.
2.5 Використання заголовних файлів
2.5.1 Поділ програми на незалежні частини
Кожна нетривіальна програма може бути розділена на відносно універсальні частини, які можуть бути використані в кількох проєктах, та частини, специфічні для конкретного проєкту. Універсальні та специфічні частини доцільно зберігати в окремих файлах.
Припустимо, ми створили програму, яка містить деякі математичні функції та демонструє їхню роботу:
#include <iostream>double cube(double x) {return x * x * x; }int factorial(unsigned short int n) {if (n > 12 || n < 0) {return -1;// Помилка }if (n <= 1) {return 1; }return n * factorial(n - 1); }int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Примітка: останній результат можна пояснити тим, що параметр n має тип unsigned
short int, тому надіслане
значення -4 автоматично конвертується в 65532.
Після успішної перевірки роботи функцій їх можна використати в декількох програмах. Звичайно, можна просто скопіювати необхідні рядки коду в інший файл. Але такий підхід має очевидні недоліки:
- якщо функції не дві, а достатньо багато, копіювання коду призводить до істотного збільшення розмірів файлу й довжини коду програм, що погано впливає на можливість контролювати сирцевий код;
- під час копіювання можна зробити помилки, загубивши необхідну частину коду, або некоректно розташувавши його в іншому файлі.
Загалом під час такого копіювання порушується один з важливих принципів належної практики програмування – принцип DRY (Don't Repeat Yourself).
Краще розташувати спільні функції в окремому файлі та надавати компілятору їхній код без здійснення фізичного копіювання.
Найпростіший шлях для реалізації цієї ідеї полягає у застосуванні директиви препроцесора
#include, яка дозволяє перед компіляцією включити сирцевий код з одного файлу всередину іншого перед
компіляцією.
Наприклад, ми можемо створити окремий файл functions.cpp та розташувати в ньому код функцій:
// functions.cpp double cube(double x) {return x * x * x; }int factorial(unsigned short int n) {if (n > 12 || n < 0) {return -1;// Помилка }if (n <= 1) {return 1; }return n * factorial(n - 1); }
В основній програмі можна скористатися директивою #include:
#include <iostream> #include "functions.cpp"int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Примітка: лапки в директиві #include вказують, що файл треба шукати в поточній теці.
Препроцесор не здійснює фізичного копіювання змісту файлу. Замість цього препроцесор створює новий вихідний текст в оперативній пам'яті.
Тепер фрагмент коду, який міститься у файлі functions.cpp, можна включити в будь-яку програму, в якій
потрібні відповідні функції.
Описаний підхід має певні недоліки:
- одні й ті ж функції перекомпілюються багато разів у різних програмах; якщо набір функцій достатньо великий, це може істотно впливати на швидкість компіляції;
- неправильний контекст включення файлу може призвести до помилок компіляції або до спотворення результатів;
- у складніших випадках код функцій може потрапити в програму декілька разів, що є неприпустимим і призведе до помилки компіляції.
Було б добре. якщо функції можна було скомпілювати окремо. Така можливість є. Можна зібрати програму з декількох одиниць трансляції. Одиниця трансляції – це результат обробки вихідного тексту препроцесором. Створений препроцесором код компілюється в так званий об'єктний модуль.
Результатом компіляції файлу functions.cpp буде об'єктний модуль functions.obj,
який містить скомпільований машинний код функцій. Лінкер зможе відшукати код цих функцій і додати його до файлу,
що буде виконуватися. Але є проблема з компілятором: він не зможе скомпілювати функцію main() без
прототипів функцій, які викликаються. Ці прототипи можна додати вручну:
#include <iostream>double cube(double );int factorial(unsigned short int );int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Додавання прототипів вручну виправдане лише в найпростіших випадках. Якщо функцій багато, таке ручне додавання буде громіздким, є джерелом потенційних помилок, істотно збільшить розміри файлу та зробить код менш наочним.
Для розв'язання цієї проблеми в мовах C і C++ запропоновано механізм так званих заголовних файлів. Заголовний
файл – це
файл з сирцевим кодом, який містить оголошення функцій і деякі визначення, які певна одиниця трансляції може надати
іншим одиницям трансляції. Зазвичай заголовний файл має розширення h (header). Для того щоб вказати
на зв'язок заголовного файлу з файлом, який містить визначення (файлом реалізації), доцільно вибрати ім'я заголовного
файлу, як збігається з ім'ям файлу реалізації, але має розширення .h. В нашому випадку до проєкту слід
додати файл functions.h:
// functions.h double cube(double );int factorial(unsigned short int );
Замість ручного копіювання прототипів заголовний файл можна додати за допомогою директиви #include:
#include <iostream> #include "functions.h"int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Включення заголовних файлів гарантує точне відтворення оголошень у всіх одиницях трансляції.
У заголовний файл можна включати такі елементи:
- іменовані простори імен
- визначення типів
- оголошення функцій
- визначення функцій з модифікатором
inline - оголошення даних (з ключовим словом
extern ), - визначення констант
- директиви препроцесору
- коментарі.
Заголовні файли не повинні містити
- визначень звичайних функцій
- визначень даних
- безіменних просторів імен.
Існують чисельні стандартні заголовні файли з описами класів та функцій. Для включення таких файлів
замість лапок слід вживати кутові дужки <> для того, щоб препроцесор шукав такі файли
в стандартних теках. В іншому випадку препроцесор починає пошук з поточної теки.
2.5.2 Стражі включення (Include Guards)
Дуже часто у вихідний текст необхідно включати більше одного заголовного файлу. Крім того, дуже часто є
необхідність включення тексту одного заголовного файлу в інший заголовний файл. Наприклад, є
необхідність включення файлу f1.h у файл f2.h, файл f3.h потребує
включення файлів f1.h та f2.h, а всі ці файли необхідні для компіляції
основної програми:
//f1.h ...//f2.h #include "f1.h" ...//f3.h #include "f1.h" #include "f2.h" ...//main.cpp #include "f1.h" #include "f2.h" #include "f3.h" ...
Препроцесор включає вміст файлу f1.h у одиницю трансляції, коли він обробляє файл
main.cpp.
Потім він включає вміст файлу f2.h, який також містить включення f1.h. Після
включення f3.h одиниця трансляції містить чотири копії тексту f1.h та дві
копії f2.h. Таке включення не має сенсу, а також може викликати помилки під час компіляції.
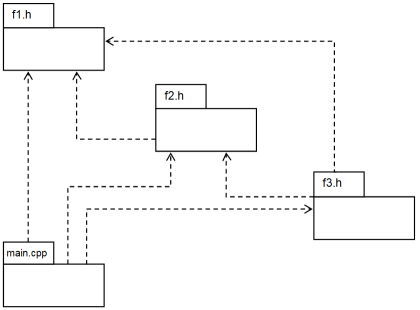
Найчастіше цю проблему вирішують за допомогою так званих стражів включення – спеціальної конструкції з директив препроцесора.
Окрім директиви #include, яка застосовувалася раніше, можна також
видалити певні частини вихідного тексту за допомогою директив #define, #ifdef та #ifndef.
Директива #define дозволяє визначити нову змінну препроцесору в будь-якому місці. В іншому місці
можна перевірити цей факт за допомогою директив #ifdef або #ifndef. Наприклад:
#define New_Name ... #ifdef New_Name// Включаємо цей код в одиницю трансляції #else// Не включаємо цього коду в одиницю трансляції #endif
За допомогою вказаних директив текст заголовного файлу f1.h можна
організувати в такий спосіб:
#ifndef F1_H #define F1_H ...// увесь вміст файлу #endif
Вперше, коли у програмі згадується включення заголовного файлу, препроцесор здійснює читання першого
рядку (#ifndef) та включає весь текст в одиницю трансляції, оскільки змінна
F1_H ще не була визначена. Окрім того, препроцесор визначає цю змінну.
Вдруге та будь-коли потім препроцесор не включає тексту заголовного файлу, оскільки змінна
F1_H вже визначена.
Ім'я, яке визначається у директиві #define, може бути довільним. Важливо тільки, щоб воно
було визначене тільки в одному заголовному файлі. В іменах змінних препроцесору не можна застосовувати
крапку.
В розглянутому вище прикладі до файлу functions.h теж слід додати стражі включення:
// functions.h #ifndef FUNCTIONS_H #define FUNCTIONS_Hdouble cube(double );int factorial(unsigned short int ); #endif
2.5.3 Створення й заголовних файлів. Оголошення глобальних змінних
Для створення заголовних файлів у середовищі Visual Studio необхідно виконати такі дії:
- вибирати
- Add New Item
у підменю- Project
- вибирати
- Header File (.h)
у вікні- Templates
- ввести нове ім'я файлу без розширення у полі
- Name
- натиснути кнопку
- Add
Можна додати новий файл реалізації аналогічним чином.
Іноді виникає ідея створити в одній одиниці трансляції глобальну змінну та використовувати її для обміну даними між функціями різних одиниць трансляції. Ідея, яка перша приходить в голову – визначити таку змінну в заголовному файлі:
int someValue;// Змінна призначена для обміну даними
Таке визначення призводить до помилки. Препроцесор включає заголовний файл в кожну одиницю трансляції й компілятор створює декілька таких змінних. Під час збирання програми виникає конфлікт імен, або створюється своя змінна для кожної одиниці трансляції.
Насправді змінну слід оголосити, а не визначити в заголовному файлі. Оголошення змінної повідомляє, що
змінна існує і визначається десь в іншому місці. Оголошення не є визначенням, не приводить до виділення
пам'яті. Для оголошення змінної без визначення використовується ключове слово
extern int someValue;// Змінна буде визначена пізніше
Змінну слід визначити в одному (і лише в одному) файлі реалізації. Тепер всі одиниці трансляції мають доступ до однієї змінної.
2.6 Простори імен
Простори імен визначають логічну структуру програми.
Простір імен являє собою іменовану область, яка може містити оголошення і визначення констант, змінних, функцій і типів, а також інших просторів імен. Простори імен дозволяють уникнути конфліктів імен. Простори імен дають механізм для логічного групування оголошень і визначень.
namespace MySpace {int k = 10;void f(int n) { k = n; } }
Елементи просторів імен можуть бути визначені окремо від своїх оголошень. Наприклад,
namespace MySpace {int k = 10;void f(int n); }void MySpace::f(int n) { k = n; }
Простори імен можуть бути вкладені в інші простори імен:
namespace FirstSpace {namespace SecondSpace {// ... } }
Починаючи з версії мови C++17 можна створювати вкладені простори імен у простіший спосіб:
namespace FirstSpace::SecondSpace {// ... }
Можна використовувати альтернативне ім'я для ідентифікації простору імен:
namespace YourSpace = MySpace;
Простори імен можна переривати й відкривати знову для подальшого розширення:
namespace FirstSpace {// перша частина }// ... інші описи namespace SecondSpace {// інший простір імен }namespace FirstSpace {// друга частина }
Оголошення одного простору імен можуть знаходитися в різних файлах.
Безіменні простори імен використовують в програмах, які збирають з декількох одиниць трансляції
Є три способи доступу до елементів простору імен:
- за допомогою явної кваліфікації доступу
- за допомогою
using -оголошення - за допомогою
using -директиви.
Перший варіант дозволяє дістатися кожного імені через ідентифікатор простору і необхідне ім'я всередині
простору, розташоване після операції дозволу видимості (::). Наприклад:
int x = MySpace::k;
Другий варіант дозволяє отримати доступ до членів простору імен в індивідуальному порядку з використанням
синтаксису
using MySpace::k;using MySpace::f;int y = k + f(k);
Третій спосіб використовують, якщо є потреба у використанні кількох (або всіх) членів простору імен. За
допомогою
using namespace MySpace;
Слід уникати використання цієї директиви через можливі конфлікти імен.
Директива
namespace NewSpace {using namespace FirstSpace;using namespace SecondSpace; }
Можна вибрати кілька імен з одного або декількох просторів імен у новому просторі імен за допомогою
namespace NewSpace {using OtherSpace::name1;using OtherSpace::name2; }
Такий простір імен може бути використаний у різних проєктах.
Простори імен у C++ не приховують дані.
Більшість компонентів стандартної бібліотеки C++ згрупована в просторі імен std. Простір
імен std містить додаткові простори імен, такі як, наприклад, std::rel_ops.
Існує спеціальний різновид просторів імен – так звані безіменні простори імен (anonymous namespaces). Наприклад,
namespace {int k;void f() { } }
Підключення такого простору неможливе ні в який спосіб. В межах фізичного файлу доступ до імен безіменного простору не обмежується і не вимагає префіксів. Поза межами файлу робота з іменами безіменного простору не можлива.
Створення безіменного простору імен і розташування в ньому функцій і змінних, які необхідні лише в цій одиниці трансляції прискорює роботу лінкера, оскільки він навіть не намагається відшукувати в безіменному просторі імена, вжиті в інших одиницях трансляції. Використання безіменних просторів також зменшує ймовірність конфліктів імен під час компонування.
Безіменні простори імен не можна розташовувати в заголовних файлах.
3 Приклади програм
3.1 Метод ділення відрізка навпіл (дихотомії)
Наведена нижче програма знаходить корінь рівняння за допомогою методу дихотомії. Алгоритм методу можна спрощено описати так:
- Визначається інтервал, на якому рівняння f(x) = 0 має один корінь.
- У циклі знаходиться середина інтервалу.
- Порівнюють знаки функції на початку й всередині інтервалу. Якщо знаки збігаються, на першій половині інтервалу немає кореня й ми переносимо початок на середину інтервалу. Якщо знаки різні, на першій половині є корінь і ми переносимо кінець інтервалу на середину.
- Цикл повторюється поки довжина інтервалу більше заданої точності.
Єдине обмеження використання методу дихотомії полягає у тому, що рівняння повинно мати рівно один корінь на заданому інтервалі.
#include <iostream> #include <cmath>using std::cout;using std::endl;using std::sin;typedef double (*FuncType)(double );double root(FuncType f,double a,double b,double eps) {double x;do { x = (a + b) / 2;if (f(a) * f(x) > 0) { a = x; }else { b = x; } }while (b - a > eps);return x; }double g(double x) {return x * x - 2; }int main() { cout << root(g, 0, 6, 0.00001) << endl; cout << root(sin, 1, 4, 0.00001) << endl;return 0; }
Як видно з наведеного коду, для отримання проміжних точок функції використано механізм зворотного виклику.
3.2 Використання декількох варіантів алгоритмів розв'язання рівняння
Попередню програму можна розширити, додавши альтернативний алгоритм пошуку кореня, наприклад, повний перебір.
Ми проходимо по інтервалу з кроком eps і виходимо з циклу, коли на маленькому інтервалі змінився знак.
Тепер користувач, наприклад, може вибрати алгоритм пошуку кореня. Код буде таким:
#include <iostream> #include <cmath>using std::cin;using std::cout;using std::endl;using std::sin;typedef double (*FuncType)(double );typedef double (*AlgorithmType)(FuncType,double ,double ,double );double dichotomy(FuncType f,double a,double b,double eps) {double x;do { x = (a + b) / 2;if (f(a) * f(x) > 0) { a = x; }else { b = x; } }while (b - a > eps);return x; }double fullSearch(FuncType f,double a,double b,double eps) {for (double x = a; x < b; x += eps) {if (f(x) * f(x + eps) <= 0) {return x + eps / 2; } }return INFINITY; }double g(double x) {return x * x - 2; }int main() { std::system("chcp 65001 > nul"); cout << "Уведіть метод розв'язання (1 - метод дихотомії, " << "2 - метод повного перебору):";int answer; cin >> answer; AlgorithmType root = nullptr;switch (answer) {case 1: root = dichotomy;break ;case 2: root = fullSearch;break ; }if (root != nullptr) { cout << root(g, 0, 6, 0.0000001) << endl; cout << root(sin, 1, 4, 0.0000001) << endl; }else { cout << "error" << endl; }return 0; }
Як видно з коду, у визначенні typedef можна використовувати попередні визначення typedef.
Виконання цієї програми може, зокрема, продемонструвати дуже низьку ефективність повного перебору.
3.3 Робота з масивом вказівників на функції
Припустимо, ми хочемо створити функцію, яка для певного значення аргументу та двох визначених функцій повертає суму значень цих функцій. Цю задачу можна розв'язати через застосування вказівників на функції.
В окремому просторі імен описуємо синонім типу вказівника на функцію, яка приймає аргумент типу
Поза створеним простором імен визначаємо функцію sqr(), яка приймає аргумент типу double та
повертає другий степінь аргументу.
У функції main() створюємо два масиви вказівників на функції описаного раніше типу. До масивів включаємо
вказівники на стандартні функції, а також на нашу функцію sqr(). Читаємо
з клавіатури значення аргументу та в циклі виводимо функцію для всіх вказівників на функції з масивів:
#include <iostream> #include <cmath>using std::cin;using std::cout;using std::endl;using std::sin;using std::cos;using std::exp;using std::sqrt;namespace Func {typedef double (*OneArgFunc)(double );double sum(OneArgFunc first, OneArgFunc second,double x) {return first(x) + second(x); } }using Func::OneArgFunc;double sqr(double x) {return x * x; }int main() {const int n = 3; OneArgFunc firstArr[n] = { sin, exp, sqr }; OneArgFunc secondArr[n] = { cos, sqr, sqrt };double x; cin >> x;for (int i = 0; i < n; i++) { cout << Func::sum(firstArr[i], secondArr[i], x) << endl; }return 0; }
Як видно з прикладу, до синоніма типу ми звертаємось за допомогою директиви using, а до функції з
простору імен Func – із застосуванням префіксу.
Розроблений код можна зробити більш універсальним, якщо визначення синоніма типу OneArgFunc і прототип
функції
sum() винести в окремий заголовний файл, а реалізацію функції
sum() – у файл реалізації. Заголовний файл SumOfFuncs.h буде таким:
// SumOfFuncs.h #ifndef SUM_OF_FUNCS_H #define SUM_OF_FUNCS_Hnamespace Func {typedef double (*OneArgFunc)(double );double sum(OneArgFunc first, OneArgFunc second,double x); } #endif
Відповідний файл реалізації:
//SumOfFuncs.cpp #include "SumOfFuncs.h"double Func::sum(OneArgFunc first, OneArgFunc second,double x) {return first(x) + second(x); }
Файл з функцією main():
// main.cpp #include <iostream> #include <cmath> #include "SumOfFuncs.h"using std::cin;using std::cout;using std::endl;using std::sin;using std::cos;using std::exp;using std::sqrt;using Func::OneArgFunc;double sqr(double x) {return x * x; }int main() {const int n = 3; OneArgFunc firstArr[n] = { sin, exp, sqr }; OneArgFunc secondArr[n] = { cos, sqr, sqrt };double x; cin >> x;for (int i = 0; i < n; i++) { cout << Func::sum(firstArr[i], secondArr[i], x) << endl; }return 0; }
4 Вправи для контролю
- Реалізувати вправи лабораторної роботи № 4 попереднього
семестру з розташуванням в окремій одиниці трансляції всіх функцій, крім
main(). - Реалізувати вправи лабораторної роботи № 4 попереднього
семестру з розташуванням в окремому просторі імен усіх функцій, крім
main(). - Створити програму, в якій користувач вибирає одну з декількох функцій та один з алгоритмів обчислення визначеного інтеграла (метод прямокутників або метод трапецій). Скористатися двома типами вказівників на функції.
5 Контрольні запитання
- Які парадигми програмування підтримує C++?
- Які є версії стандарту C++?
- Що таке інтегроване середовище розробки?
- Як створити синонім для типу?
- Що таке вказівник на функцію?
- Для чого використовують вказівники на функції?
- Як визначити вказівник на функцію?
- Що таке одиниця трансляції?
- Як здійснюється використання директиви
#define? - Які правила розподілу сирцевого коду між заголовним файлом і файлом реалізації?
- У чому різниця між включенням стандартних заголовних файлів і заголовних файлів користувача?
- Що таке стражі включення?
- Що таке простір імен?
- Як об'єднати кілька просторів імен в один?
- Як визначити псевдонім для простору імен?