Laboratory Training 1
Pointers to Functions and Header Files
1 Training Tasks
1.1 Output of the Table of Values of Function
Create a separate translation unit in which you should implement the function of outputting a table of values of a certain function with a certain step. Function parameters are: the beginning, end of the interval, step and pointer to the function, the values of which will be displayed in the table. In the header file, you must declare the type of pointer to function and the prototype of the value table output function. In the implementation file, define the value table output function.
In another translation unit, you should place the functions for which you want to output values in a table, as
well as the main() function, which outputs tables of values to at least two different functions. One of the functions
for testing is a function determined from the task of the first
laboratory training and
implemented in the fourth laboratory training.
1.2 Individual Assignment
Write a program that implements exhaustive search of some value according to an individual assignment. Necessary value can be found by testing intermediate values of a function. Use typedefs and pointers to functions.
The source code should be split into two translation units. The first translation unit will be represented by both
header file and implementation file. The typedef definition, as well as declaration of function
that searches necessary value, should be placed into header file. The definition of this function will take place
in implementation file corresponding to header file. The testing function, as well as main() function,
should be placed into another translation unit.
| Index of variant (from students list) |
Rule of searching: |
|---|---|
|
1, 17 |
Maximum value of the second derivative |
|
2, 18 |
Minimum value of the first derivative |
|
3, 19 |
The least root |
|
4, 20 |
The greatest root |
|
5, 21 |
The sum of minimum and maximum values |
|
6, 22 |
The product of minimum and maximum values |
|
7, 23 |
Roots count |
|
8, 24 |
The least root of the second derivative |
|
9, 25 |
Minimum value of the second derivative |
|
10, 26 |
Maximum value of the first derivative |
|
11, 27 |
The least root of the first derivative |
|
12, 28 |
The greatest root of the first derivative |
|
13, 29 |
The greatest root of the second derivative |
|
14, 30 |
The sum of minimum and maximum values |
|
15, 31 |
Definite integral of a function on an interval by the rectangle method |
|
16, 32 |
Definite integral of a function on an interval by the trapezoidal method |
You should check the functionality of the program on at least two arbitrary functions. One of the functions can be standard.
A root is the value of x at which a function returns zero.
Note: To calculate first derivative of y(x), you can use the following formula:
Where Δx is some tiny value, such as 0.0000001.
1.3 Working with an Array of Pointers to Functions
In a separate namespace, describe an alias for a type of pointer to a function that takes two arguments of type
double and returns a result of type double. In the same
namespace, implement a function with result of type void, which receives as a parameter
the previously described pointer to a function and the values of two arguments and displays the values of the arguments
and the value of the function on the screen.
Outside the created namespace, define a function that takes two arguments of double type
and returns the sum of the second powers of the arguments.
In the main() function, create an array of pointers to functions of the previously described type.
In the array, place pointers to the standard functions of the cmath header file, which receive
two arguments, as well as a pointer to the previously created function for calculating the sum of the second powers.
Read the values of two arguments from the keyboard and output the arguments and function for all pointers to functions
from the array in a loop.
Recommended functions of cmath header file that take two type arguments and return a result of type
double:
pow()an arbitrary power of a number;hypot()the value of the hypotenuse for the two specified legs of a right triangle;fmax()the maximum of two values;fmin()minimum of two values;
Demonstrate different ways to connect namespace elements.
2 Instructions
2.1 C++ Language and its Versions
C++ is a high-level universal programming language that simultaneously supports several programming paradigms:
- Imperative programming is a programming paradigm that involves representing a program as a sequence of instructions. These instructions describe how the system should perform certain actions. The developer clearly describes the steps that need to be taken to achieve a certain goal. To implement the imperative programming paradigm, C++ provides a number of syntactic constructs such as statement-expressions, conditional constructs, loops, and label transitions.
- Procedural programming is a programming paradigm in which a program consists of a set of procedures or functions. Each function has a fixed set of output parameters and a result. Procedures (functions) work with their own set of local variables. At the same time, the possibility of using global variables that determine the state of the program is supported. The C++ language provides all the necessary tools to implement procedural programming.
- Modular programming is an approach to software development in which a program is broken down into separate independent physically or logically separated parts. Each unit provides a specific set of types and operations. C++ implements physical grouping of code through the mechanism of header files and implementation files and logical grouping of code through the use of namespaces. Starting with the C++20 version, the concept of modules was added, which provide both physical and logical code grouping.
- Object-oriented programming (OOP) is a programming paradigm in which a program is represented by a
set of interacting objects. Objects are characterized by state (fields) and
behavior (methods). A class is a description of an object type. C++ provides powerful means of creating custom types: classes and structures. Additionally, you can create enumerations and units. - Generic programming is a programming paradigm that allows you to create functions and classes that can support independent work with different data types without being bound to a specific type. Generic programming is implemented in C++ through the templates' mechanism.
- Functional programming is a programming paradigm in which the basic building block is a function. The work consists in the manipulation of functions: recursion, callback, etc. Starting with the C++11 version, there is a special type of functional objects: lambda expressions.
The task of this course is to master the tools of modular, object-oriented, generalized and functional programming provided by the C++ language. In addition, the Standard Template Library (STL) tools will be covered.
Bjarne Stroustrup started work on a language similar to C, but one that supports object-oriented programming, since 1979. The name C++ appeared in 1983. In 1985, the first version of the C++ language was published.
The second version of the language appeared in 1989. The first version of the language was significantly expanded. In 1990, the current state of the language was published. The published description of the language actually became the basis for the future C++ language standard.
Like most modern languages, C++ is standardized. There are several versions of the international standard of the C++ language:
- In 1998, the C++98 standard (the third version of the language) was released. The standard was approved by the Object Management Group (OMG), an international consortium, and a minor update (C++03) was released in 2003. In addition to all previously proposed language constructs, the standard included the Standard Template Library (STL), which became part of the C++ Standard Library. To implement modularity, the concept of namespace was added.
- In 2011, the C++11 standard was released, which included significant extensions to the language (new loop syntax, lambda expressions, etc.) and the Standard Library. Minor updates were made in the C++14 version. Various new additions were introduced in C++17.
- The C++20 standard was approved on September 4, 2020, and officially published on December 15, 2020. In particular, the standard introduces the mechanism of modules.
- The C++23 language standard was approved in February 2020 and officially published in October 2024.
2.2 Integrated Development Environments for C++ Development
2.2.1 Overview
From the beginning, creating programs in the C++ language involved separate preparation of the source code using a text editor, running the compiler, linker, and directly the program for debugging and testing on the command line. The first C++ compiler, Cfront, was developed by Bjarne Stroustrup in 1983.
In order to improve the productivity of programmers, integrated development environments are created. Integrated Development Environment (IDE) is a set of software tools that provide developers with all the tools they need to develop software, integrated into a single application. Main components of IDE:
- text editor,
- compiler, debugger,
- project assembly tools,
- version control tools,
- means of automating tasks.
In addition to tools from Microsoft, various IDEs for developing programs in C++ were popular at different times. Example:
- Borland C++Builder is an integrated development environment created by Borland International. The IDE is designed primarily for rapid application development (RAD). In addition to full C++ syntax support, developers were provided with a visual components library (VCL) for building Windows applications.
- Dev-C++ is an IDE for developing programs in C++ for the Windows platform. The environment provided basic features such as a text editor, compiler, and debugging tools.
- Eclipse CDT. Eclipse is a popular integrated development environment for various programming languages, primarily Java. With the C/C++ Development Tooling (CDT) plug-in, Eclipse provided convenient tools for developing C++ programs.
- Code::Blocks is an open and free IDE for developing C++ programs, which provides a convenient user interface and basic capabilities for working with C++ projects.
- Qt Creator: Qt Creator is an integrated development environment specifically designed for developing applications using the Qt library. It provided convenient tools for working with Qt and the C++ programming language.
- CLion is an IDE from JetBrains that includes an intelligent code editor, debugging tools, support for version control systems, and other features aimed at improving developer productivity.
- Xcode is the main development environment for macOS and has support for development in C++ along with other programming languages.
For developing C++ programs, you can also use Microsoft Visual Studio Code (VS Code), a free cross-platform text editor with extensive capabilities for software development. It supports a large number of programming languages, including C++, and provides tools for debugging, syntax highlighting, code completion, working with the version control system (Git), and much more. Since VS Code is not a programming environment, but a code editor, to create and debug C++ programs, in addition to VS Code itself, you need to install compilation tools and other necessary utilities. Microsoft Visual Studio Code should not be confused with Microsoft Visual Studio.
Microsoft Visual C++ is an integrated development environment (IDE) and compiler for the C++ programming language. Below are some of the versions of Visual C++:
- Visual C++ 1.0 (1993): This was the first version of Visual C++ released in 1993. It included a development environment and a compiler for the C++ programming language.
- Visual C++ 2.0 (1994): This version was released in 1994 and included support for Windows 95, a new C++ compiler, and an improved development environment.
- Visual C++ 4.0 (1995): Version 4.0 was released in 1995 with the release of Windows 95. It included support for 32-bit Windows applications, ActiveX components, and COM objects.
Later versions were part of the Microsoft Visual Studio integrated environment.
2.2.2 Features and Versions of MS Visual Studio
Microsoft Visual Studio is an integrated development environment (IDE) that supports various programming languages, including C++, C#, Visual Basic .NET, F#, and others. The following are early versions of Microsoft Visual Studio:
- Visual Studio 97: This was the first version of Visual Studio to include an integrated development environment for the Win32 platform.
- Visual Studio 6.0: Released in 1998 and included a development environment for various programming languages such as Visual Basic 6.0, Visual C++, Visual FoxPro, and others.
- Visual Studio .NET 2002: This version was released with the .NET platform and included support for programming languages that run on the CLR (Common Language Runtime), such as C#, Visual Basic .NET, and C++/CLI.
Later versions were released on average once every two years. The latest version of Visual Studio 2026 provides artificial intelligence capabilities. The capabilities of the integrated environment have been improved; tools for working with the latest versions of programming languages have been implemented.
Traditionally, Visual Studio versions support the latest versions of C++.
2.3 Typedefs
C++ enables you to create an alias for existing type name by using the typedef keyword, which
stands for type definition.
As a result, you create synonym for exiting type. It is important to distinguish creation of synonym from creating
a new type (definition of structures, enumerations, and classes). Definition of a synonym starts with typedef keyword, followed
by the existing type, followed by new name (identifier). For example,
typedef unsigned long int Integer;typedef int IntArray[15];
creates the new name Integer that you can use anywhere you might have written unsigned long int.
The IntArray identifier can be used for definition of an array of 15 integer values:
Integer c;int f(Integer k); IntArray a;// int a[15];
A typedef declaration is interpreted in the same way as a variable or function declaration,
but the identifier becomes a synonym for the type.
For type aliases, you can use names that start with an uppercase letter to indicate that it is not a variable
or a standard type. But in this case, the names can be confused with the names of custom types (structures, enumerations,
classes). An alternative rule for determining typedef alias names is to add the ending
_t, for example:
typedef unsigned int integer_t;typedef int array15_t[15];
Next, both options will be used.
Type aliases allow you to hide implementation details that may change. For example, if during further development
it turns out that a signed long integer should be used instead of an unsigned long integer, it is enough to change
the typedef definition:
typedef signed long int Integer;
After recompiling, the name Integer in the program will be interpreted as a long signed integer.
The typedef definition allows you to build shorter names. Suppose the following arrays are
created in different places of the program:
unsigned long long int ** a1[20];// unsigned long long int ** a2[20];
In this case, it is advisable to create a typedef definition:
typedef unsigned long long int ** arr[20];
Now the variables can be defined like this:
arr a1;// arr a2;
It should be remembered that such definitions sometimes reduce the readability of the code.
Sometimes synonyms of standard types are defined in libraries. These names allow you to hide implementation details
that may change. In addition, the use of synonyms allows you to indicate the connection of a variable, parameter
or function with the means of some library. For example, the name size_t is defined in the Standard
C++ Library:
typedef unsigned long size_t;
Note: depending on the platform, size_t may be defined differently, for example:
typedef unsigned long long size_t;
If a variable index is created to work with Standard library collections, it is better to use size_t:
size_t index;
The popular Standard library type string is also synonymous with a certain template type.
Starting with C++11, an alternative syntax for creating type aliases based on using declaration
has been added to the language. For example, instead of defining
typedef int Integer;
the following construct can be proposed:
using Integer =int ;
The new form of creation type alias has the following advantages:
- better readability;
- more logical syntactic sequence (name always on the left);
- support for template aliases.
Templates in C++ will be discussed later.
2.4 Pointers to Functions
2.4.1 Definition of Pointers to Functions
A pointer to a function is an address where that function's executable code is stored; that is, the address to which control is transferred when that function is called. Just as an array name is a constant pointer to the first element of the array, a function name can be treated as a constant pointer to the function. It is possible to declare a pointer variable that points to a function, and to invoke the function by using that pointer.
A pointer to a function must point to a function of the appropriate return type and signature. In the definition
int (*funcPtr)(double );
funcPtr is declared to be a pointer that points to a function that takes a floating point parameter
and returns integer value. The parentheses around *funcPtr are necessary. Without the first pair of
parentheses this would declare a function that takes a double and returns a pointer to an int.
The declaration of a pointer to function will always include the return type and the parentheses indicating types
of the parameters.
You can assign a pointer to function to a specific function by assigning to the function name without the parentheses. Use the pointer to function just as you would the function name. The pointer to function must agree in return value and signature with the function to which you assign it. For example:
int round(double x){ return x + 0.5; }int main() {int (* funcPtr)(double );double y; cin >> y; funcPtr= round; cout << funcPtr(y);return 0; }
The pointer to function does not need to be dereferenced, though you are free to do so. Therefore, if pFunc is
a pointer to a function, and you assign pFunc to a matching function, you can invoke that function
with either
pFunc(x);
or
(*pFunc)(x);
The two forms are identical.
The typedef declaration can be used to declare types of pointers to functions:
typedef int (*FuncType)(int ); FuncType pf;
2.4.2 Use of Pointers to Functions
You can declare arrays of pointers to functions. For example, you can create the following function:
double f(double x) {return 1 / x; }
An array of pointers to the function and the value of that function can then be created, and some standard functions for value 2 of argument can be output in a loop:
double (*func[])(double ) = { f, sin, cos, exp };for (int i = 0; i < 4 ; i++) { cout << func[i](2) << endl; }
The use of pointers to functions can increase the efficiency of solving problems in which it is necessary to choose from a set of fixed functions. For example, it is necessary to implement a program in which the user enters the start and end of an interval, as well as a step, then selects a function (enters its number) and receives a table of values of arguments and functions. Without using pointers to functions, the program code might look like this:
#include <iostream> #include <cmath>int main() {double from, to, step; std::cout << "Enter the start, end, and step for the function value table:"; std::cin >> from >> to >> step; std::cout << "Enter the function number (1 - sin, 2 - cos, 3 - sqrt):";int index; std::cin >> index;if (index < 1 || index > 3) {return -1; }for (double x = from; x <= to; x += step) {double y = 0;switch (index) {case 1: y = std::sin(x);break ;case 2: y = std::cos(x);break ;case 3: y = std::sqrt(x); } std::cout << x << "\t" << y << std::endl; }return 0; }
The disadvantage of the implementation is the choosing the function at each step of the cycle. This, in particular, slows down the program. It is possible to define a function before the start of the loop by using a pointer to the function:
#include <iostream> #include <cmath>int main() {double from, to, step; std::cout << "Enter the start, end, and step for the function value table:"; std::cin >> from >> to >> step; std::cout << "Enter the function number (1 - sin, 2 - cos, 3 - sqrt):";int index; std::cin >> index;if (index < 1 || index > 3) {return -1; }// For the default implementation, we use a lambda expression: double (*f)(double ) = [](double ) {return 0.0; };switch (index) {case 1: f = std::sin;break ;case 2: f = std::cos;break ;case 3: f = std::sqrt; }for (double x = from; x <= to; x += step) { std::cout << x << "\t" << f(x) << std::endl; }return 0; }
You can also use an array of functions:
#include <iostream> #include <cmath>int main() {double from, to, step; std::cout << "Enter the start, end, and step for the function value table:"; std::cin >> from >> to >> step; std::cout << "Enter the function number (1 - sin, 2 - cos, 3 - sqrt):";int index; std::cin >> index;if (index < 1 || index > 3) {return -1; }const int n = 3;double (*f[n])(double ) = { std::sin, std::cos, std::sqrt };for (double x = from; x <= to; x += step) { std::cout << x << "\t" << f[index - 1](x) << std::endl; }return 0; }
2.4.3 Callback
Pointers to functions are more particularly used as types of functions' argument. The callback mechanism involves defining a function, which is called not directly in the part of the code where it is defined, but from another part of the code, where you can send a pointer to this function, for example, as a parameter of another function.
For example, there is a certain universal algorithm, which for its work requires the implementation of calls to another function. The function in this case acts as some information along with numerical and other arguments. These can be different tasks, for example:
- implementation of a universal algorithm for solving an equation
- finding maxima and minima
- derivative calculation
- calculation of the definite integral
- finding inflection points
- processing of an event related to user actions, etc.
Pointers to functions are primarily used to implement this mechanism.
For example, some function (algorithm) requires another function as a parameter:
void someAlgorithm(void (*f)(double )) {double z;//... f(z);//... }
In another part of the code we create the necessary function and pass its address as a parameter:
void g(double x) {//... }int main() {//... someAlgorithm(g);//... }
Example 3.1 illustrates the use of the callback mechanism to solve an equation using Bisection method.
2.5 Header Files
2.5.1 Dividing a Program into Independent Parts
Every nontrivial program can be divided into relative universal parts that can be used in several projects, and project-specific parts that realize features of particular system. It is a good idea to store universal and problem specific parts separate files.
Assume that we created a program that contains some mathematical functions and demonstrates their operation:
#include <iostream>double cube(double x) {return x * x * x; }int factorial(unsigned short int n) {if (n > 12 || n < 0) {return -1;// Error }if (n <= 1) {return 1; }return n * factorial(n - 1); }int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Note: the last result can be explained by the fact that the parameter n has type unsigned
short int, so the value sent (-4) is
automatically converted to 65532.
After successfully testing the functions, they can be used in multiple programs. Of course, you can simply copy the necessary lines of code to another file. But this approach has obvious disadvantages:
- if there are not two functions, but many, copying the code leads to a significant increase in file size and program code length, which has a negative impact on the ability to control the source code;
- when copying, you can make mistakes by losing a necessary part of the code or placing it incorrectly in another file.
In general, such copying violates one of the important principles of good programming practice – the DRY (Don't Repeat Yourself) principle.
It is better to place shared functions in a separate file and provide the compiler with their code without physically
copying them. The simplest way to divide source code into several files is using of #include preprocessor
directive that allows programmer to insert the text of one source file into another before compiling
procedure.
For example, we can create a separate file (functions.cpp) and place the function code in it:
// functions.cpp double cube(double x) {return x * x * x; }int factorial(unsigned short int n) {if (n > 12 || n < 0) {return -1;// Error }if (n <= 1) {return 1; }return n * factorial(n - 1); }
In the main program, we can use the #include directive:
#include <iostream> #include "functions.cpp"int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Note: The quotes in the #include directive indicate that the file should be searched in
the current folder.
Preprocessor does not implement a physical copying of a file contents into another file. Instead of such copying, preprocessor creates a new source text in memory.
Now the code fragment contained in the file functions.cpp can be included in any program that requires the corresponding functions.
The described approach has certain disadvantages:
- the same functions are recompiled many times in different programs; if the set of functions is large enough, this can significantly affect compilation speed;
- incorrect file inclusion context can lead to compilation errors or corrupted results;
- in more complex cases, function code may enter the program multiple times, which is unacceptable and will lead to a compilation error.
It would be nice if functions could be compiled separately. This is possible. A single project can contain several translation units. A translation unit appears as a result of processing of source file by preprocessor. The code created by the preprocessor is compiled into a so-called object module.
The result of compiling the functions.cpp file will be an object module functions.obj that contains
the compiled machine code of the functions. The linker will be able to find the code for these functions and add
it to the file to be executed. But there is a problem with the compiler: it will not be able to compile the main() function
without the prototypes of the functions that are called. These prototypes can be added manually:
#include <iostream>double cube(double );int factorial(unsigned short int );int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Adding prototypes manually is only reasonable in the simplest cases. If there are many functions, such manual addition will be cumbersome, is a source of potential errors, significantly increases the file size, and make the code less readable.
To solve this problem, the C and C++ languages have proposed a mechanism called header files. A header
file is
a source code file that contains function declarations and some definitions that a particular translation unit can
provide to other translation units. Typically, a header file has the extension h (header). In order
to indicate the relationship of the header file to the file containing the definitions (the implementation file),
it is advisable to choose a header file name that matches the name of the implementation file, but has the extension .h.
In our case, the functions.h file should be added to the project:
// functions.h double cube(double );int factorial(unsigned short int );
Instead of manually copying prototypes, we can add the header file using the #include directive:
#include <iostream> #include "functions.h"int main() { std::cout << cube(6) << std::endl;// 216 std::cout << factorial(7) << std::endl;// 5040 std::cout << factorial(14) << std::endl;// -1 std::cout << factorial(-4) << std::endl;// -1 }
Including header files ensures accurate reproduction across all translation units.
Header file can contain
- named namespaces
- type definitions
- function declarations
- inline function definitions
- data declarations (with
externkeyword) - constant definitions
- preprocessor directives
- comments.
Header file cannot contain
- ordinary function definitions
- data definitions
- anonymous namespaces.
There are numerous standard header files that contain declarations of standard classes and functions. The names
of such files in #include directive must be written in <> instead of "".
That causes preprocessor to look for such files in standard directories. Otherwise, preprocessor searches the header
starting from current directory.
2.5.2 Include Guards
Because your programs will use various functions from many libraries, many header files will be included in each
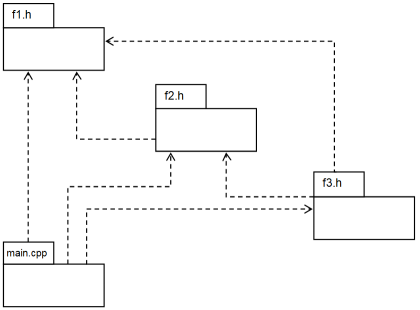
file. Also, header files often need to include one another. For example, header file f2.h needs to
include file f1.h, header file f3.h needs to include files f1.h and f2.h,
and we need to include all of them into our source file:
/f1.h ...//f2.h #include "f1.h" ...//f3.h #include "f1.h" #include "f2.h" ...//main.cpp #include "f1.h" #include "f2.h" #include "f3.h" ...
Preprocessor includes contents of f1.h into translation unit by processing of main.cpp.
Then it includes contents of f2.h into translation unit. The text of f2.h contains inclusion
of f1.h. Therefore, translation unit contains two copies of f1.h. After inclusion of f3.h,
translation unit contains four copies of f1.h and two copies of f2.h. Those inclusions
are unmeaning and dangerous because some pieces of code can be placed into translation unit two, three, or more
times. That is legal for simple declarations and illegal for definitions of inline functions and other definitions.
The traditional solution of a problem is to insert include guards (inclusion guards) in header files – a
special construct of preprocessor directives. In addition to the #include directive used earlier,
it is also possible to remove some parts of a source text using #define, #ifdef and #ifndef directives.
A preprocessor variable with a specific name have been declared anywhere in source file using #define directive.
It is possible to check for this fact using #ifdef or #ifndef directives. For example,
#define New_Name ... #ifdef New_Name// this code is written into translation unit #else// this code is not written into translation unit #endif
The text
of the header file f1.h can be organized as follows:
#ifndef F1_H #define F1_H ...// the whole file goes here #endif
The first time program includes this file, preprocessor reads the first line and the test evaluates to TRUE;
that is, variable F1_H is not yet defined. So, it goes ahead and defines it and then includes the entire
file.
The second time program includes the f1.h file, preprocessor reads the first line and the test evaluates
to FALSE; F1_H has been defined. It therefore skips to the next #endif (at
the end of the file). Thus, it skips the entire contents of the file.
The actual name of the defined symbol (F1_H) is not important, although it is customary to use the
filename with the dot (.) changed to an underscore.
In the example above, include guards should also be added to the functions.h file:
// functions.h #ifndef FUNCTIONS_H #define FUNCTIONS_Hdouble cube(double );int factorial(unsigned short int ); #endif
2.5.3 Creating Header Files. Declaration of Global Variables
To create header files in Microsoft Visual Studio, follow the following steps:
- choose
- Add New Item
in- Project
submenu - choose
- Header File (.h)
in- Templates
window - type new file name without extension in
- Name
field - press
- Add
button
You can add new implementation file in analogous way.
Sometimes the idea arises to create a global variable in one translation unit and use it to exchange data between the functions of different translation units. The first idea that comes to mind is to define the following variable in the header file:
int someValue;// The variable is intended for data exchange
Such a definition leads to an error. The preprocessor includes a header file in each translation unit, and the compiler creates several such variables. When linking a program, a name conflict occurs, or a variable is created for each translation unit.
In fact, the variable should be declared, not defined in the header file. The variable declaration reports that
the variable exists and is defined elsewhere. Declaration is not a definition, it does not lead to memory allocation.
The extern keyword is used to declare a variable without definition:
extern int someValue;// the variable will be defined later
The variable should be defined in one (and only one) implementation file. Now all translation units have access to one variable.
2.6 Namespaces
Namespaces determine a logical structure of a program.
A namespace is an optionally-named declarative region. Namespaces can avoid name conflicts. Namespaces give a mechanism for expressing logical grouping.
namespace MySpace {int k = 10;void f(int n) { k = n; } }
Namespace members can be defined separately from their declarations. For example,
namespace MySpace {int k = 10;void f(int n); }void MySpace::f(int n) { k = n; }
Namespaces can be nested in other namespaces:
namespace FirstSpace {namespace SecondSpace {// ... } }
Starting with C++17, you can create nested namespaces in a simpler way:
namespace FirstSpace::SecondSpace {// ... }
You can use an alternate name to refer to a namespace identifier:
namespace YourSpace = MySpace;
Namespaces are discontinuous and open for additional development. If you redeclare a namespace, the effect is that you extend the original namespace by adding new declarations:
namespace FirstSpace {// first part }// ... other declarations namespace SecondSpace {// another namespace }namespace FirstSpace {// second part }
Related declarations can span across several files.
There are three ways to access the elements of a namespace:
- the explicit access qualification
- the
using-declaration - the
using-directive.
In the first case, you can use the namespace identifier together with the scope resolution operator (::)
followed by the member name. For example,
int x = MySpace::k;
In the second case, you can access namespace members individually with the using-declaration
syntax. When you make a using-declaration, you add the declared identifier to the
local namespace:
using MySpace::k;using MySpace::f;int y = k + f(k);
If you want to use several (or all of) the members of a namespace, C++ provides an easy way to get access to the
complete namespace. The using-directive specifies that all identifiers in a namespace are in
scope at the point that the using-directive statement is made. For example,
using namespace MySpace;
You must avoid using this directive because of possible name conflicts.
The using-directive can be used if you want to join several namespaces:
namespace NewSpace {using namespace FirstSpace;using namespace SecondSpace; }
You can select some names from one or more namespaces in new namespace with using-declaration:
namespace NewSpace {using OtherSpace::name1;using OtherSpace::name2; }
Such namespace can be used in multiple projects.
Namespaces in C++ do not cover data. Once namespace was connected with the help of using directive, all names declared in the namespace can be used as global names without any restriction.
Most of the components of the Standard C++ Library are grouped under namespace std. Namespace std is
subdivided into additional namespaces such as std::rel_ops.
There is a special kind of namespaces – the so-called anonymous namespaces (nameless namespaces, unnamed namespaces). For example,
namespace {int k;void f() { } }
It is impossible to connect such space in any way. Within a physical file, access to anonymous space names is not restricted and does not require prefixes. It is not possible to work with anonymous names outside the file.
Creating an anonymous namespace and locating the functions and variables needed only in this translation unit speeds up the linker's work, because it does not even try to find names used in other translation units in the anonymous space. Using anonymous spaces also reduces the probability of name conflicts during linking.
Anonymous namespaces cannot be placed in header files.
3 Sample Programs
3.1 Bisection (Dichotomy) Method
The following program finds roots of an equation using dichotomy method. The algorithm of the method can be simply described as follows:
- The interval on which the equation f(x) = 0 has one root is determined.
- In a loop, the middle of the interval is calculated.
- The signs of the function at the beginning and inside the interval are compared. If the signs match, there is no root on the first half of the interval, and we move the origin to the middle of the interval. If the signs are different, the first half has a root, and we move the end of the interval to the middle.
- The cycle is repeated until the length of the interval is greater than the specified precision.
The only restriction on use of dichotomy method is that the equation must have exactly one root on a given interval.
#include <iostream> #include <cmath>using std::cout;using std::endl;using std::sin;typedef double (*FuncType)(double );double root(FuncType f,double a,double b,double eps) {double x;do { x = (a + b) / 2;if (f(a) * f(x) > 0) { a = x; }else { b = x; } }while (b - a > eps);return x; }double g(double x) {return x * x - 2; }int main() { cout << root(g, 0, 6, 0.00001) << endl; cout << root(sin, 1, 4, 0.00001) << endl;return 0; }
As can be seen from the above code, a callback mechanism is used to obtain intermediate values of the function.
3.2 Using Several Variants of Equation Solving Algorithms
The previous program can also be extended by adding an alternative algorithm for finding the root, for example,
full search. We go through the interval with a step eps and exit the loop when the sign has changed
on a small interval.
Now the user, for example, can choose the root search algorithm. The code will be as follows:
#include <iostream> #include <cmath>using std::cin;using std::cout;using std::endl;using std::sin;typedef double (*FuncType)(double );typedef double (*AlgorithmType)(FuncType,double ,double ,double );double dichotomy(FuncType f,double a,double b,double eps) {double x;do { x = (a + b) / 2;if (f(a) * f(x) > 0) { a = x; }else { b = x; } }while (b - a > eps);return x; }double fullSearch(FuncType f,double a,double b,double eps) {for (double x = a; x < b; x += eps) {if (f(x) * f(x + eps) <= 0) {return x + eps / 2; } }return INFINITY; }double g(double x) {return x * x - 2; }int main() { cout << "Enter the solution method (1 - dichotomy method, " << "2 - the method of full search):";int answer; cin >> answer; AlgorithmType root =nullptr ;switch (answer) {case 1: root = dichotomy;break ;case 2: root = fullSearch;break ; }if (root !=nullptr ) { cout << root(g, 0, 6, 0.0000001) << endl; cout << root(sin, 1, 4, 0.0000001) << endl; }else { cout << "error" << endl; }return 0; }
As you can see from the code, typedef can use previous typedef definitions.
Running this program can, in particular, show very low efficiency of a full search.
3.3 Working with an Array of Pointers to Functions
Suppose we want to create a function that, for a given argument and two defined functions, returns the sum of the values of these functions. This problem can be solved through the use of pointers to functions.
In a separate namespace, we describe an alias for a type of pointer to a function that takes argument of type double and
returns a result of type double. In the same namespace, we implement a function with
result of type double, which receives as a parameters the previously described pointers
to functions and the value of argument and returns the sum of the values of these functions.
Outside the created namespace, define a sqr() function that takes one argument of double type
and returns the second power of the argument.
In the main() function, we create two arrays of pointers to functions of the previously described
type. In the arrays, we place pointers to the standard functions of the cmath header file, which receive
one argument, as well as a pointer to the previously created function for calculating the second power.
We read the values of an argument from the keyboard and output the function for all pointers
to functions from arrays in
a loop:
#include <iostream> #include <cmath>using std::cin;using std::cout;using std::endl;using std::sin;using std::cos;using std::exp;using std::sqrt;namespace Func {typedef double (*OneArgFunc)(double );double sum(OneArgFunc first, OneArgFunc second,double x) {return first(x) + second(x); } }using Func::OneArgFunc;double sqr(double x) {return x * x; }int main() {const int n = 3; OneArgFunc firstArr[n] = { sin, exp, sqr }; OneArgFunc secondArr[n] = { cos, sqr, sqrt };double x; cin >> x;for (int i = 0; i < n; i++) { cout << Func::sum(firstArr[i], secondArr[i], x) << endl; }return 0; }
As can be seen from the example, we refer to typedef using the using directive, and refer to the function
from the Func namespace with the use of a prefix.
The developed code can be made more universal if the definition of the typedef OneArgFunc and the
prototype of sum() function
are placed in a separate header file, and the implementation of thr sum() function is placed in an implementation
file. The header file SumOfFuncs.h will look like this:
// SumOfFuncs.h #ifndef SUM_OF_FUNCS_H #define SUM_OF_FUNCS_Hnamespace Func {typedef double (*OneArgFunc)(double );double sum(OneArgFunc first, OneArgFunc second,double x); } #endif
The corresponding implementation file:
//SumOfFuncs.cpp #include "SumOfFuncs.h"double Func::sum(OneArgFunc first, OneArgFunc second,double x) {return first(x) + second(x); }
File with main() function:
// main.cpp #include <iostream> #include <cmath> #include "SumOfFuncs.h"using std::cin;using std::cout;using std::endl;using std::sin;using std::cos;using std::exp;using std::sqrt;using Func::OneArgFunc;double sqr(double x) {return x * x; }int main() {const int n = 3; OneArgFunc firstArr[n] = { sin, exp, sqr }; OneArgFunc secondArr[n] = { cos, sqr, sqrt };double x; cin >> x;for (int i = 0; i < n; i++) { cout << Func::sum(firstArr[i], secondArr[i], x) << endl; }return 0; }
4 Exercises
- Implement exercises of training #4 placing
into separate translation unit all functions, apart from
main(). - Implement exercises of training #4 placing
into separate namespace all functions, apart from
main(). - Create a program in which the user selects one of several functions and one of the algorithms for calculating the definite integral (method of rectangles or method of trapezoids). Use two types of pointers to functions.
5 Quiz
- What programming paradigms does C++ support?
- What are the versions of the C++ standard?
- What is an integrated development environment?
- How to create synonym for existing type?
- What is pointer to function?
- What is usage of pointers to functions?
- How to define pointer to function?
- What is translation unit?
- What is the usage of #define directive?
- What are rules of distribution of source code between header file and implementation file?
- What is the difference between inclusion of standard header files and user header files?
- What are include guards?
- What is namespace?
- How to join several namespaces into one?
- How to define alias for existing namespace?