Лабораторна робота 2
Робота з переліками та структурами
1 Завдання на лабораторну роботу
1.1 Перелік для представлення місяців року
Створити перелік для представлення місяців року. Реалізувати та продемонструвати перевантаження операцій ++
і -- так, щоб після грудня йшов січень, а перед січнем – грудень.
1.2 Точки в тривимірному просторі
Створити структуру для опису точки в тривимірному просторі (тип точки). Написати програму, яка обчислює відстань між двома точками. Для обчислення відстані створити функцію з двома параметрами типу структури для представлення точок.
1.3 Представлення й обробка даних про студентів у масиві
Створити структуру для представлення даних про студента. Структура повинна містити такі елементи даних:
- номер студентського посвідчення (
unsigned int); - прізвище (рядок у вигляді
масиву символів); - оцінки за останню сесію у вигляді масиву цілих від 0 до 100 (оцінки за предметами).
Реалізувати функцію яка здійснює виведення даних про студента у консольне вікно. Першим параметром функції повинна бути структура, яка описує студента.
Реалізувати функції, які отримують масив вказівників на студентів і довжину масиву і здійснюють
- сортування масиву за ознакою, яка наведена в індивідуальному завданні;
- пошук даних про студентів, які відповідають умові, наведеній в індивідуальному завданні.
- виведення всіх елементів масиву в консольне вікно.
Під час сортування масиву структур замість обміну місцями двох структур здійснювати обмін місцями елементів масиву вказівників.
Створити масив студентів. Створити масив вказівників на студентів, заповнивши його адресами структур з масиву студентів. Продемонструвати сортування й пошук студентів.
Індивідуальні завдання:
| №№ студента у списку |
Умова сортування | Умова вибору даних |
|---|---|---|
| 1 | За алфавітом | З середнім балом в інтервалі "64" – "74" |
| 2 | За збільшенням середнього балу | З довжиною прізвища понад 7 літер |
| 3 | За зменшенням довжини прізвища | З середнім балом в інтервалі "90" – "100" |
| 4 | За зменшенням номера студентського посвідчення | Прізвище починається з літери "А" |
| 5 | За зменшенням середнього балу | Прізвище закінчується літерою "а" |
| 6 | За збільшенням суми оцінок | З непарною довжиною прізвища |
| 7 | За збільшенням довжини прізвища | З непарними номерами студентських посвідчень |
| 8 | За алфавітом | З парними номерами студентських посвідчень |
| 9 | За алфавітом у зворотному порядку | Оцінок "A" більше, ніж оцінок "D" |
| 10 | За збільшенням номера студентського посвідчення | Прізвище містить літеру "е" |
| 11 | За зменшенням добутку оцінок | З непарною довжиною прізвища |
| 12 | За збільшенням добутку оцінок | З довжиною прізвища менш ніж 8 літер |
| 13 | За алфавітом | З парною сумою оцінок |
| 14 | За алфавітом у зворотному порядку | З непарними номерами студентських посвідчень |
| 15 | За алфавітом | З середнім балом в інтервалі "75" – "81" |
| 16 | За збільшенням середнього балу | З довжиною прізвища менш ніж 7 літер |
| 17 | За збільшенням довжини прізвища | З середнім балом в інтервалі "82" – "89" |
| 18 | За збільшенням номера студентського посвідчення | Прізвище починається з літери "А" |
| 19 | За збільшенням середнього балу | Прізвище закінчується літерою "а" |
| 20 | За збільшенням суми оцінок | З парною довжиною прізвища |
| 21 | За збільшенням довжини прізвища | З парними номерами студентських посвідчень |
| 22 | За алфавітом у зворотному порядку | З парними номерами студентських посвідчень |
| 23 | За алфавітом | Оцінок "A" більше, ніж оцінок "E" |
| 24 | За збільшенням номера студентського посвідчення | Прізвище містить літеру "о" |
| 25 | За зменшенням добутку оцінок | З парною довжиною прізвища |
| 26 | За зменшенням добутку оцінок | З довжиною прізвища менш ніж 9 літер |
| 27 | За алфавітом у зворотному порядку | З непарною сумою оцінок |
| 28 | За алфавітом | З непарними номерами студентських посвідчень |
1.4 Робота з однобічно зв'язаним списком чисел
Написати програму, яка забезпечує файлове введення та виведення і включає індивідуальне завдання лабораторної роботи № 5 курсу "Основи програмування (частина 1)". Слід реалізувати такі дії:
- визначення константи (
n) яка визначає кількість стовпців двовимірного масиву - відкриття файлу для читання (файл повинен бути підготовлений за допомогою текстового редактора)
- читання цілих чисел до кінця файлу і зберігання їх у зв'язаному списку
- створення двовимірного масиву в динамічній пам'яті; кількість рядків повинна бути обчислена на основі кількості зчитаних з файлу значень та визначеної кількості стовпців
- заповнення двовимірного масиву рядок за рядком; відсутні елементи останнього рядка повинні бути заповнені нулями
- видалення елементів зв'язаного списку з динамічної пам'яті
- реалізація індивідуального завдання лабораторної роботи № 5 курсу "Основи програмування (частина 1)".
- зберігання результатів в новому файлі
- видалення масивів операцією
delete
1.5 Робота з двобічно зв'язаним списком даних про студентів (додаткове завдання)
Реалізувати завдання 1.3, розташувавши дані про студентів у динамічній пам'яті, а відповідні вказівники розташувати у двобічно зв'язаному списку. Реалізувати сортування методом вибору. Не використовувати масивів. Коректно видалити дані з динамічної пам'яті.
2 Методичні вказівки
2.1 Користувацькі типи
Засоби C ++, зокрема, об'єктно-орієнтовані, націлені в першу чергу на створення користувацьких типів. Мова C++ дозволяє створювати власні типи, використання яких може бути не менш зручним і більш виразним, ніж використання стандартних типів, що існують.
У більшості випадків для створення користувацьких типів застосовують класи. Але іноді також можна використовувати інші мовні конструкції – переліки, структури й об'єднання.
2.2 Переліки
Тип переліку визначає набір цілих констант. Перелік може бути визначений за допомогою ключового слова
enum
Можна створити безіменні та іменовані переліки. Безіменний перелік фактично є списком констант. Наприклад,
enum { red, green, blue };
Такий перелік еквівалентний визначенню констант:
const int red = 0;const int green = 1;const int blue = 2;
Необхідні значення можна визначити явно. Значення наступних елементів обчислюють шляхом додавання одиниці:
enum { one = 1, three = 3, four, nine = 9, ten };// four == 4, ten == 10
Іменований перелік у C++ визначає новий тип даних. Цей новий тип може бути використаний для визначення змінних:
enum Colors { red, green, blue }; Colors c = blue;
На відміну від опису typedefColors, тільки
значення red, green та blue. Але навпаки, присвоєння цілим змінним
значень типу Colors є цілком коректним. Змінні таких типів можна використовувати у виразах.
Colors c; c = 1;// Помилка! c = green;// OK int i = c;// OK i = c + 1;// OK
Для переліків можна перевантажувати деякі операції, наприклад ++ і --.
Перевантаження операцій – це потужний механізм визначення поведінки для об'єктів користувацьких типів. Завдяки
перевантаженню операцій над об'єктами можна виконувати дії з використанням більшості операторів мови С++. Наприклад,
якщо для об'єкта a перевантажена операція додавання до нього цілого значення, у програмі можна
використовувати вираз a + 1. В такий спосіб можна створювати типи об'єктів, робота з якими мало відрізняється
від роботи з примітивними типами. Для класів можна перевантажувати майже всі операції, для переліків – лише деякі.
Для того щоб операція вважалась перевантаженою, необхідно створити так звану операторну функцію. Ім'я цієї функції
складається зі слова operator, після якого розташовано оператор, який ми хочемо перевантажити.
Аргументи операторної функції – операнди операції. Докладно синтаксис операторних функцій буде розглянуто під
час розгляду синтаксису класів. У прикладі 3.1 перевантаження операцій реалізовано для переліку "День тижня".
Оскільки традиційні переліки додають імена констант у глобальну область видимості, збільшується ймовірність конфліктів імен. Для уникнення таких конфліктів у сучасних версіях C++ для звернення до окремих констант переліку зазвичай використовують префікс (ім'я типу переліку та операція області видимості):
Colors c = Colors::green;
Починаючи з версії C++11, виникла можливість обмеження видимості елементів переліку областю видимості самого переліку.
Створюють спеціальний різновид переліку – перелік з областю видимості (scoped enum), додаючи
ключове слово class або struct після enum:
enum class Colors { red, green, blue };
Тепер до елементів переліку можна звертатися тільки через ім'я переліку, бо тепер елементи не є глобальними константами:
Colors c1 = Colors::green; Colors c2 = green;// Помилка!
2.3 Структури
Структури дозволяють об'єднати кілька елементів даних різних типів. З такою групою можна працювати як з одним цілим. Наприклад:
struct {int i;double d; } pair;
Змінна pair містить два елементи даних (поля), з якими можна працювати,
використовуючи імена, до яких ми звертаємось через крапку:
pair.d = 1.5; pair.i = 3;double y = pair.d + pair.i;
Аналогічна конструкція присутня у мові C.
Окремі поля – це фактично змінні відповідних типів, над якими можна виконувати всі дії, дозволені для цих типів.
У мові С++ зазвичай спочатку визначають новий тип структури даних і пізніше створювати змінні цього типу. Після
ключового слова
struct Pair {int i;double d; };// крапка з комою обов'язкова
Можна створити змінну типу Pair:
Pair p;
Мова C не підтримує такого опису типу. У мові C можна створювати типи структур, але для цього застосовують інший синтаксис:
typedef struct {int i;double d; } Pair;
Цей синтаксис також доступний у C++, але вважається небажаним.
Типи даних окремих елементів можуть бути однаковими, наприклад:
struct Point {int x;int y; };
В цьому випадку імена елементів даних можна вказувати через кому:
struct Point {int x, y; };
Структура, як і масив – це складений тип даних. Загальною рисою складених типів даних є можливість звернення до групи даних через одне ім'я. Складений тип даних може включати багато елементів. Але різні складені типи передбачають різні шляхи створення змінних і надають різні можливості.
- Усі елементи масиву повинні бути одного типу, елементи структури можуть бути різних типів.
- Масив описується через визначення загальної кількості елементів, тоді як всі елементи структур описуються й іменуються окремо.
- Звертатися до елементів масиву необхідно через визначення індексу, а до елементів структури – через імена.
Наприклад, можна створити змінну типу структури:
struct {double x, y; } point_struct;
Можна виконати типові дії над елементами даних:
point_struct.x = 5; point_struct.y = point_struct.x; std::cout << point_struct.x << point_struct.y;
Альтернативне рішення – створити масив point_arr і виконувати аналогічні дії:
double point_arr[2]; point_arr[0] = 5; point_arr[1] = point_arr[0]; std::cout << point_arr[0] << point_arr[1];
Для забезпечення більшої схожості можна, наприклад, визначити константи x та y:
const int x = 0;const int y = 1;double point_arr[2]; point_arr[x] = 5; point_arr[y] = point_arr[x]; std::cout << point_arr[x] << point_arr[y];
Але розбіжності залишаються. Існує ще багато синтаксичних відмінностей. Головне те, що структури створюють для опису сутності, різні атрибути якої мають різний сенс. Масиви створюють для роботи з великою кількістю однотипних сутностей.
Зазвичай структури використовують для опису сутностей реального світу. Наприклад, можна описати тип структури для представлення країни:
struct Country {char name[20];double area;long population; };
Тепер замість роботи з окремими змінними ми створюємо одну змінну. Це забезпечує цілісність даних:
Country France;// France є змінною типу Country
Структури, як і інші визначені користувачем типи даних, зазвичай визначаються в глобальній області видимості. Синтаксис мови C++ дозволяє створювати змінні нового типу безпосередньо після його визначення.
struct Country {char name[20];double area;long population; } France;// France є змінною типу Country
Визначення змінних разом з типом (або без імені типу) не рекомендуються у мові C++. Кращий підхід передбачає окреме визначення типів даних і змінних.
Під час створення змінної типу структури можна здійснити її ініціалізацію. Значення елементів ініціалізуються в порядку опису:
Country France = { "France", 551695, 67750000 };
Починаючи з C++20 можна ініціалізувати елементи даних структури (або частину елементів даних), явно вказуючи крапку та відповідне ім'я (designated initializers), наприклад:
Country Germany = { .area = 357022, .population = 83497147 };
Поле name залишилося без ініціалізації (порожній рядок).
Можна також опустити знак рівності:
Country Germany { .area = 357022, .population = 83497147 };
На відміну від масивів, оператор присвоювання виконує поелементне копіювання однієї структури в іншу:
Country someCountry; someCountry = France;// поелементне копіювання
Значення елементів даних структури можна отримати в традиційний спосіб, наприклад:
char * name = France.name;double area = France.area;long population = France.population;
Починаючи з версії C++17 в синтаксисі мови з'явилася нова конструкція так звана структурована прив'язка (Structured binding). Структуровані прив'язки дозволяють розпаковувати структури в окремі змінні під час оголошення групи змінних. В нашому випадку можна створити змінні та ініціалізувати їх у такий спосіб:
auto [name, area, population] = France;
Фактично ми створили змінні необхідних типів і можемо їх використовувати:
std::cout << name << std::endl;// France std::cout << area << std::endl;// 551695 std::cout << population << std::endl;// 67750000
Техніка отримання змінних з елементів складених типів може також бути застосована до масивів:
double point3D[3] = { 1, 2, 3 };auto [x, y, z] = point3D; std::cout << x << std::endl;// 1 std::cout << y << std::endl;// 2 std::cout << z << std::endl;// 3
Можна створювати вказівники на структури. Для того щоб описати вказівник на структуру, застосовують такий синтаксис:
Country* pCountry = &someCountry; (*pCountry).area = 551695;
Дужки обов'язкові, оскільки пріоритет операцій передбачає спочатку отримання елемента, а потім розіменування:
*pCountry.area = 551695;// Помилка. pCountry - не структура, area - не вказівник
Для спрощення доступу до елементів структур, на які вказує вказівник,
використовується спеціальна операція ->. Наприклад:
Country *pCountry = &someCountry; pCountry->area = 551695;
На відміну від масивів, об'єкти типу структури передаються у функції за значенням. Це означає, що функція
працює з копіями об'єктів. Це також стосується елементів масивів, які розташовані всередині структури. Вони
також копіюються під час присвоєння одній структурі іншої або під час передачі параметрів. Розглянемо такий
приклад. Структура містить масив фіксованої довжини n. Спеціальна допоміжна функція
print() здійснює виведення елементів масиву цілих:
const int n = 4;struct Array {int arr[n]; };void print(int *arr_n) {for (int * p = arr_n; p < arr_n + n; p++) { cout << *p << " "; } cout << endl; }
Функція tryToModify() отримує структуру як параметр, змінює значення елементів масиву, збільшуючи
їх на одиницю, а потім здійснює виведення значень елементів на екран:
void tryToModify(Array a) {for (int i = 0; i < n; i++) { a.arr[i]++; } print(a.arr);// 2 3 4 5 }
У функції main() здійснюється ініціалізація структури, виклик функції та виведення значень
елементів масиву після виклику:
int main() { Array a = { { 1, 2, 3, 4 } };// вкладені фігурні дужки обов'язкові tryToModify(a); print(a.arr);// 1 2 3 4 return 0; }
Значення елементів не змінилися. Якщо необхідно змінити значення елементів структури всередині тіла функції, слід використовувати аргументи типу посилання:
void tryToModify(Array &a) {for (int i = 0; i < n; i++) { a.arr[i]++; } print(a.arr);// 2 3 4 5 }int main() { Array a = { { 1, 2, 3, 4 } }; tryToModify(a); print(a.arr);// 2 3 4 5 return 0; }
Навіть якщо не потрібно змінювати дані всередині функції, можна використовувати посилання на константні типи, що підвищить продуктивність програми через копіювання адреси замість величезного блоку даних:
struct LargeData {// Деяка велика структура };void someFunc(const LargeData& data) {// ... };
Структура може містити в собі іншу структуру.
Якщо структура містить низку змінних, які можуть мати лише дуже невелике число можливих значень, можна заощадити пам'ять за допомогою бітових полів, вказавши максимальний розмір поля у бітах. Оголошення бітового поля містить ім'я деякого цілого типу, за яким слідує ім'я поля, а потім двокрапка, а потім розмір бітового поля.
struct Flags {unsigned int logical : 1;// один біт unsigned int tinyInt : 3;// крихітне ціле };
За допомогою бітових полів кілька значень можна зберігати в одному байті. Це не працює, якщо бітові поля чергуються з небітовими полями. Бітові поля можна також використовувати у визначеннях класів.
На відміну від мови програмування C, структури у C++ можуть мати функції-елементи. Взагалі структури підтримують увесь синтаксис класів. Єдина відмінність полягає в тому, що усталено елементи структури є відкритими, але це можна змінити за допомогою відповідних директив. Оскільки приховування даних є дуже важливим з точки зору об'єктно-орієнтованого програмування, для створення повноцінних користувацьких типів використовують саме класи, а не структури. Структури, як правило, використовуються для групування даних, а не замість класів.
2.4 Об'єднання
Об'єднання (union
union FloatAndInt {float f;int i; }; FloatAndInt fi; fi.i = 2; fi.f = 100; cout << fi.i << endl;// 1120403456 fi.i = 3; cout << fi.f << endl;// 4.2039e-45
Об'єднання може бути використане для створення масивів, елементи яких мають різні типи. Крім того, можна використати об'єднання для кодування інформації, а також для аналізу внутрішнього представлення даних. У наведеному вище прикладі число 1120403456, якщо його перевести у двійкову систему, показує внутрішнє представлення числа 100.0 з рухомою крапкою.
Можна створювати анонімні об'єднання:
union {int a;const char * p; }; a = 1; p = "name";// a і p немає сенсу використовувати одночасно
Після використання p значення a буде зіпсоване.
Об'єднання може містити функції-елементи.
Іноді об'єднання використовують як частину даних структур для опису взаємно несумісних даних. Наприклад, можна створити структуру для опису деякого студента. Залежно від форми навчання (контрактна / бюджетна) студент або сплачує за навчання певну суму, або потенційно може отримувати стипендію. Структура може бути такою:
struct Student {char name[30];char surname[30];bool isContractForm;union {double paymentAmount;int scholarship; }; };
Компілятор не в змозі відстежити зв'язок між булевим полем isContractForm і тим, яка з гілок використовується.
Це програміст повинен контролювати сам, і тому такий підхід дуже ймовірно призводить до виникнення логічних помилок
у програмі.
Можливості застосування об'єднань істотно обмежені. Використання поліморфізму надає більш коректний спосіб для зберігання в масивах даних різних типів, тому зараз об'єднання використовують не дуже часто.
2.5 Сортування масивів структур з використанням вказівників
Структури, які описують об'єкти реального світу, можуть бути достатньо великими за розмірами. Відповідно копіювання структури в нову змінну може вимагати багато часу. Якщо в програмі здійснюється, наприклад, сортування масиву структур за певною ознакою, таке копіювання може виконуватися дуже багато разів. Тим більше якщо послідовно сортувати за різними критеріями сортування, це ще збільшить час виконання програми.
Існує спосіб підвищення ефективності виконання програм, які працюють з масивами структур. Ідея полягає в такому:
- створюємо допоміжний масив вказівників, який заповнюємо адресами елементів масиву структур;
- в алгоритмі сортування, або в іншому алгоритмі, пов'язаному з обміном місцями елементів масиву структур здійснюється модифікація масиву вказівників;
- доступ до структур здійснюється через масив указівників, а не безпосередньо.
Цей підхід продемонстровано у прикладі 3.4.
2.6 Використання зв'язаних списків
Одна з найпоширеніших задач, які розв'язуються програмістами, є представлення та обробка послідовностей даних. Більшість задач реального світу може бути розв'язана через використання масивів. Але іноді застосування масивів не є достатнім через такі недоліки:
- додавання нових елементів у кінець масиву не може бути здійснене без додаткових зарезервованих елементів; якщо немає таких елементів, ми повинні створити новий масив і скопіювати вміст старого масиву в новий
- додавання елементів всередину або видалення елементів, як правило, вимагає копіювання багатьох елементів даних.
Інший підхід до подання послідовностей забезпечує так званий зв'язаний список (linked list), або ланцюг. Для реалізації зв'язаного списку необхідно створити структуру, яка містить безпосередньо дані й вказівник на інший елемент цього типу:
struct Node { Data data; Node *next; };
де Data – це деякий відомий тип даних. Для додавання нового елемента між тими, що існують, слід
створити цей елемент у динамічній пам'яті, а потім змінити значення вказівників у сусідніх елементах.
Наприклад, для зберігання цілих значень слід описати таку структуру (ланку ланцюга):
struct Node {int data; Node *next; };
Для того щоб створити зв'язаний список, необхідно створити вказівник на початок списку (першу ланку). Для зручності можна також окремо зберігати вказівник на останню ланку. Крім того, придасться вказівник на певну поточну ланку. Поки ці вказівники ні на що не вказують:
Node* head =nullptr ; Node* tail =nullptr ; Node* node =nullptr ;
Тепер до майбутнього списку можна додати перший елемент. Припустимо, необхідно додати значення цілої змінної
k. Створюємо нову ланку в динамічній пам'яті та вказуємо на неї:
int k = 1; node =new Node(); node->data = k; node->next =nullptr ; head = node; tail = node;
Далі, якщо треба, додаємо другий та інші елементи в кінець списку:
k = 2; node =new Node(); node->data = k; node->next =nullptr ; tail->next = node; tail = node;
Вивести значення елементів списку можна за допомогою циклу:
node = head;while (node !=nullptr ) { std::cout << node->data << " "; node = node->next; } std::cout << std::endl;
Якщо треба додати елемент всередині списку, не треба переписувати елементи, які вже існують, на нове місце. Достатньо перевизначити вказівники, які зберігаються в елементах списку. Наприклад, ми хочемо додати новий елемент зі значенням 3 після першого:
Node* previous = head; k = 3;
Створюємо новий елемент і змінюємо вказівники:
node =new Node(); node->data = k; node->next = previous->next; previous->next = node;
Можна так зобразити додавання ланки всередині списку:
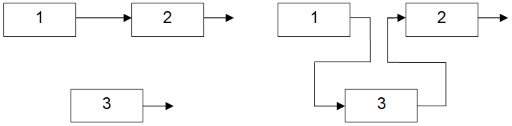
Аналогічно можна видалити елемент після вказаного. Не слід забувати про необхідність видалення елементу з динамічної пам'яті:
node = previous->next; previous->next = node->next;delete node;
Можна так зобразити видалення ланки:

Наведений нижче цикл дозволяє видалити всі наявні елементи:
while (head !=nullptr ) { node = head; head = head->next;delete node; }
Приклад 3.4 показує, як працювати зі зв'язаними списками.
Існують також двобічно зв'язані списки – списки, в яких кожен елемент вказує не тільки на наступний, але й на попередній елемент. Крім того, існують циклічні списки (однобічно зв'язані й двобічно зв'язані).

Зв'язаний список – це різновид динамічних структур даних. Іншими прикладами таких структур є черги, стеки й бінарні дерева. Приклад бінарного дерева:

3 Приклади програм
3.1 Перелік для представлення днів тижня
Припустимо, є тип переліку:
enum DayOfWeek { Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday };
Для перевантаження префіксної операції ++ в тому ж просторі імен, де визначено тип
DayOfWeek,
повинна бути реалізована така функція:
// Перевантаження префіксної операції ++ DayOfWeekoperator ++(DayOfWeek& day) {if (day == Saturday) {// окремий випадок day = Sunday; }else { day = (DayOfWeek) (day + 1);// всі інші дні }return day; }
Для перевантаження постфіксної операції ++ необхідно реалізувати функцію з двома параметрами:
// Перевантаження постфіксної операції ++ DayOfWeekoperator ++(DayOfWeek& day,int ) { DayOfWeek oldDay = day;// зберігаємо попередній день operator ++(day);// викликаємо попередню функцію return oldDay;// повертаємо попередній день }
У списку формальних параметрів int
Весь код програми буде таким:
#include <iostream>enum DayOfWeek { Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday };// Перевантаження префіксної операції ++ DayOfWeekoperator ++(DayOfWeek& day) {if (day == Saturday)// окремий випадок { day = Sunday; }else { day = (DayOfWeek) (day + 1);// всі інші дні }return day; }// Перевантаження постфіксної операції ++ DayOfWeekoperator ++(DayOfWeek& day,int ) { DayOfWeek oldDay = day;// зберігаємо попередній день operator ++(day);// викликаємо попередню функцію return oldDay;// повертаємо попередній день }// Отримання назв днів тижня const char * getName(DayOfWeek day) {switch (day) {case Sunday:return "Неділя";case Monday:return "Понеділок";case Tuesday:return "Вівторок";case Wednesday:return "Середа";case Thursday:return "Четвер";case Friday:return "П\'ятниця"; default:return "Субота"; } }int main() { std::system("chcp 65001 > nul");// Послідовно виводимо дні від середи до наступного понеділка for (DayOfWeek d = Wednesday; d != Tuesday; d++) { std::cout << getName(d) << std::endl; }return 0; }
3.2 Відстань між точками
У наведеному нижче прикладі, ми створюємо структуру, яка представляє точку на екрані. Програма обчислює відстань між двома точками.
#include <iostream> #include <cmath>struct Point {int x, y; };double sqr(double x) {return x * x; }double distance(Point p1, Point p2) {return std::sqrt(sqr(p1.x - p2.x) + sqr(p1.y - p2.y)); }int main() { Point p1 = {1, 2}; Point p2 = {4, 6}; std::cout << distance(p1, p2);return 0; }
3.3 Робота з однобічно зв'язаним списком
Наведена нижче програма читає числа з рухомою крапкою з текстового файлу і поміщає ці числа в новий файл у зворотному
порядку. Дані вводяться до кінця файлу. Під час завантаження даних створюється тимчасовий однобічно зв'язаний
список. Структура Node використовується
для представлення конкретних елементів списку. Завантажені дані переписуються в новий масив, а потім тимчасові структури
даних знищуються.
#include <fstream>using std::ifstream;using std::ofstream;// Ланка зв'язаного списку: struct Node {double data; Node* next; };// Функція зчитує зі вказаного файлу числа // та повертає вказівник на нульовий елемент масиву. // Масив створюється всередині функції, його елементи // розташовуються в динамічній пам'яті // Параметр count після завершення функції містить довжину масиву double * readFromFile(const char * fileName,int & count) {// Підготовка зв'язаного списку до роботи та створення файлового потоку: Node* head =nullptr ; Node* tail =nullptr ; Node* node; ifstream in(fileName);double d; count = 0;// лічильник чисел, які зчитані з файлу while (in >> d) {// читання до кінця файлу count++;// Створення нового елемента списку: node =new Node; node->data = d; node->next =nullptr ;if (tail ==nullptr ) { head = node; }else { tail->next = node; } tail = node; }// Створення й заповнення масиву чисел: double * arr =new double [count]; node = head;for (int i = 0; i < count; i++) { arr[i] = node->data; node = node->next; }// Видалення з динамічної пам'яті елементів зв'язаного списку: while (head !=nullptr ) { node = head; head = head->next;delete node; }return arr; }// Записує елементи масиву arr довжини count // у вказаний текстовий файл void outToFile(const char * filename,double * arr,int count) { ofstream out(filename);for (int i = count - 1; i >= 0; i--) { out << arr[i] << " "; } }int main() {int count = 0;double * arr = readFromFile("Numbers.txt", count); outToFile("Results.txt", arr, count);delete [] arr;return 0; }
Припустимо, заздалегідь створено текстовий файл з ім'ям "Numbers.txt", який містить значення,
розділені пропусками, символами табуляції або символами нового рядка:
0.1 22.2 -3 11 -9 144 1000.1 1 1.0 12.95 -3 5 4 3 55 2
Цей файл слід розмістити у теці проєкту.
Після виконання програми ми отримаємо в теці проєкту новий файл "Results.txt" з таким вмістом
2 55 3 4 5 -3 12.95 1 1 1000.1 144 -9 11 -3 22.2 0.1
3.4 Робота з масивом структур
У програмі, яку ми створимо, описується структура для представлення міста. Місто характеризується назвою, назвою країни, в якій знаходиться, назвою області, де знаходиться місто та кількістю населення.
У програмі треба створити масив з кількох міст, та реалізувати такі функції:
- сортування міст за кількістю населення;
- пошук міст, які належать до певної області;
- виведення інформації про міста.
Для кращого розуміння коду та для забезпечення можливості його багаторазового використання окремі дії (сортування, пошук, виведення) доцільно реалізувати у вигляді окремих функцій. Для підвищення ефективності роботи з даними сортування здійснюється не для масиву міст, а для масиву вказівників на міста.
Код програми буде таким:
#include <iostream> #include <cstring>// Структура для опису міста struct City {char name[30];char country[30];char region[30];int population; };// Здійснює виведення даних про місто. // Для підвищення ефективності використовуємо посилання на константний об'єкт void printCity(const City& city) { std::printf("Мiсто: %s. Країна: %s. Регіон: %s. Населення: %d\n", city.name, city.country, city.region, city.population); }// Здійснює сортування за населенням // Замість модифікації масиву міст, змінюємо масив вказівників void sortByPopulation(City** arr,int size) {bool mustSort;// повторюємо сортування // якщо mustSort дорівнює true do { mustSort =false ;for (int i = 0; i < size - 1; i++) {if (arr[i]->population > arr[i + 1]->population) {// Обмінюємо елементи City* temp = arr[i]; arr[i] = arr[i + 1]; arr[i + 1] = temp; mustSort =true ; } } }while (mustSort); }// Здійснює виведення даних про всі міста. // Доступ до міст здійснюємо через масив указівників void pintCities(City** arr,int size) {for (int i = 0; i < size; i++) { printCity(*arr[i]); } std::cout << "\n"; }// Здійснює виведення даних про міста, // які знаходяться в певній області void printIf(City cities[],int size,const char * region) {for (int i = 0; i < size; i++) {if (std::strcmp(cities[i].region, region) == 0) { printCity(cities[i]); } } }int main() { std::system("chcp 65001 > nul");const int n = 4;// Створюємо і заповнюємо масив міст: City cities[n] = { { "Харкiв", "Україна", "Харкiвська область", 1421125 }, { "Полтава", "Україна", "Полтавська область", 284942 }, { "Лозова", "Україна", "Харкiвська область", 54618 }, { "Суми", "Україна", "Сумська область", 264753 } };// Створюємо і заповнюємо масив указівників: City* pointers[n];for (int i = 0; i < n; i++) { pointers[i] = &cities[i]; } std::cout << "Початкові дані:\n"; pintCities(pointers, n); sortByPopulation(pointers, n); std::cout << "Відсортовані дані:\n"; pintCities(pointers, n); std::cout << "Міста в Харківській області:\n"; printIf(cities, n, "Харкiвська область");return 0; }
Як видно з коду, під час сортування здійснюється обмін місцями елементів масиву вказівників. У масиві структур нічого не змінюється.
3.5 Робота з двобічно зв'язаним списком
Попередній приклад можна реалізувати через використання зв'язаних списків. Використання двобічно зв'язаного списку дозволить розширити функціональність програми.
Структуру для опису міста та функцію виведення даних про місто на консоль можна скопіювати з прикладу 3.4. Далі додаємо структури для представлення ланки списку та списку в цілому. Для підвищення ефективності дій, пов'язаних з обміном місцями й сортуванням дані про міста доцільно розташувати в динамічній пам'яті та зберігати в ланках списку вказівники замість безпосередньо даних.
Весь код програми буде таким:
#define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <cstring>// Структура для опису міста struct City {char name[30];char country[30];char region[30];int population; };// Виводить дані про місто void printCity(const City& city) { std::printf("Мiсто: %s. Країна: %s. Регіон: %s. Населення: %d\n", city.name, city.country, city.region, city.population); }// Ланка зв'язаного списку: struct Node { City *data = { }; Node* previous =nullptr ; Node* next =nullptr ; };// Зв'язаний список: struct List { Node* head =nullptr ; Node* tail =nullptr ; };// Додає новий вказівник в кінці списку void addLast(List& list, City* pCity) { Node* node =new Node; node->data = pCity;if (list.tail !=nullptr ) { list.tail->next = node; node->previous = list.tail; }else { list.head = node; } list.tail = node; }// Обмінює дані двох елементів списку void swapData(Node* first, Node* second) { City *temp = first->data; first->data = second->data; second->data = temp; }// Здійснює сортування методом бульбашки void bubbleSort(List& list) {if (list.head ==nullptr ) {return ; }bool mustSort; Node* current; Node* lastSorted =nullptr ;// відстежує останній відсортований вузол do { mustSort =false ; current = list.head;while (current !=nullptr && current->next != lastSorted) {if (current->data->population > current->next->data->population) { swapData(current, current->next); mustSort =true ; } current = current->next; } lastSorted = current;// зменшує діапазон для наступного проходу }while (mustSort); }// Видаляє з динамічної пам'яті елементи зв'язаного списку і дані про міста void disposeList(List& list) {while (list.head !=nullptr ) { Node *node = list.head; list.head = list.head->next;delete node->data;delete node; } list.head ==nullptr ; list.tail ==nullptr ; }// Здійснює виведення даних про всі міста void printCities(List& list) { Node* node = list.head;while (node !=nullptr ) { printCity(*node->data); node = node->next; } std::cout << std::endl; }// Здійснює виведення даних про міста, // які знаходяться в певній області void printIf(List& list,const char * region) { Node* node = list.head;while (node !=nullptr ) {if (std::strcmp(node->data->region, region) == 0) { printCity(*node->data); } node = node->next; } std::cout << std::endl; }// Створює новий об'єкт типу City в динамічній пам'яті // та заповнює поля необхідними даними. // Вказівник на об'єкт додається у список void addCity(List& list,const char * name,const char * country,const char * region,int population) { City* pCity =new City; std::strcpy(pCity->name, name); std::strcpy(pCity->country, country); std::strcpy(pCity->region, region); pCity->population = population; addLast(list, pCity); }int main() { std::system("chcp 65001 > nul"); List list; addCity(list, "Харкiв", "Україна", "Харкiвська область", 1421125); addCity(list, "Полтава", "Україна", "Полтавська область", 284942); addCity(list, "Лозова", "Україна", "Харкiвська область", 54618); addCity(list, "Суми", "Україна", "Сумська область", 264753); std::cout << "Початкові дані:\n"; printCities(list); bubbleSort(list); std::cout << "Відсортовані дані:\n"; printCities(list); std::cout << "Міста в Харківській області:\n"; printIf(list, "Харкiвська область"); disposeList(list);return 0; }
Директива #define _CRT_SECURE_NO_WARNINGS необхідна для забезпечення коректної компіляції strcpy() в середовищі MS Visual Studio.
Можна також додати функції додавання вказівника на початку списку, вставки, видалення й виведення даних у зворотному порядку:
// Додає новий вказівник на початку списку void addFirst(List& list, City* pCity) { Node* node =new Node; node->data = pCity;if (list.head !=nullptr ) { node->next = list.head; node->next->previous = node; }else { list.tail = node; } list.head = node; }// Додає новий вказівник після вказаного елемента списку void insert(List& list, Node* after, City* pCity) { Node* node =new Node; node->data = pCity;if (after !=nullptr ) { node->next = after->next;if (after->next !=nullptr ) { after->next->previous = node; }else { list.tail = node; } after->next = node; node->previous = after; } }// Видаляє вказаний елемент зі списку void remove(List& list, Node* node) {if (node !=nullptr ) {if (node->previous ==nullptr ) { list.head = node->next; }else { node->previous->next = node->next; }if (node->next ==nullptr ) { list.tail = node->previous; }else { node->next->previous = node->previous; }delete node->data;delete node; } }// Здійснює виведення даних про всі міста у зворотному порядку void printBackward(List& list) { Node* node = list.tail;while (node !=nullptr ) { printCity(*node->data); node = node->previous; } std::cout << std::endl; }
Пропонується самостійно здійснити перевірку розширеної функціональності програми.
4 Вправи для контролю
- Визначити перелік для представлення сезонів року. Реалізувати та продемонструвати перевантаження операцій
++і--. - Визначити структуру для представлення двох цілих чисел, а потім створити та викликати функцію, яка отримує як аргумент структуру створеного типу та обчислює добуток елементів структури.
- Визначити структуру для представлення навчального закладу. Створити масив навчальних закладів. Здійснити сортування масиву за іменами.
5 Контрольні запитання
- Які синтаксичні конструкції надає C++ для створення користувацьких типів?
- Для чого використовують безіменні переліки?
- Що таке перелік з областю видимості?
- Визначте поняття структури.
- У чому різниця між структурами й масивами?
- Чому слід розташувати крапку з комою після дужки, яка закриває тіло структури?
- Як надіслати структури до функцій?
- Що таке бітові поля?
- У яких випадках бітові поля підвищують ефективність програми?
- У чому полягають особливості об'єднань і для чого їх використовують?
- У чому потенційна небезпека використання об'єднань?
- Чому доцільно використовувати масиви вказівників під час сортування масивів структур?
- Що таке динамічні структури даних?
- Які переваги зв'язаних списків в порівнянні з масивами?
- Які недоліки зв'язаних списків в порівнянні з масивами?