Лабораторна робота 4
Робота з узагальненнями та колекціями
1 Завдання на лабораторну роботу
1.1 Індивідуальне завдання
До ієрархії класів, створеної під час реалізації індивідуального завдання лабораторної
роботи № 3 додати похідні класи, які представляють першу з сутностей індивідуального завдання. Перший з них
зберігає дані у за допомогою списку (ArrayList), другий за допомогою множини (SortedSet).
Для сортування списку скористатися засобами класу Collections та інтерфейсу List.
Працюючи з множиною, слід послідовно створювати варіанти множини, впорядковані за різними критеріями.
Здійснити тестування обох реалізацій. Результати виконання програм повинні збігатися.
1.2 Перелік для опису місяців року
Створити перелік "Місяць". Необхідно визначати у конструкторі та зберігати кількість днів (для
невисокосного року). Додати методи отримання попереднього та наступного місяця, а також функцію, яка повертає
сезон для кожного місяця. Передбачити виведення місяців українською (російською) мовою. Створити статичну
функцію виведення даних про усі місяці. Протестувати переліку в функції main() тестового класу.
1.3 Створення бібліотеки узагальнених функцій для роботи з масивами
Створити клас зі статичними узагальненими методами, які реалізують таку функціональність:
- обмін місцями двох груп елементів
- обмін місцями усіх пар сусідніх елементів (з парним і непарним індексом)
- заміна групи елементів іншим масивом елементів
Здійснити демонстрацію роботи усіх методів з використанням даних різних типів (Integer, Double,
String) .
1.4 Створення бібліотеки узагальнених функцій для роботи зі списком чисел
Створити клас, який містить статичні узагальнені функції для реалізації таких дій зі списком чисел (об'єктів,
похідних від Number):
- знаходження індексу першого нульового елемента
- визначення кількості від'ємних чисел
- повернення останнього від'ємного елементу
Здійснити тестування всіх функцій на списках чисел різних типів.
1.5 Пошук різних слів у реченні
Увести речення, створити колекцію (SortedSet) різних слів речення та вивести ці слова в
алфавітному порядку.
1.6 Дані про користувачів
Представити дані про користувачів у вигляді асоціативного масиву (ім'я / пароль) з припущенням, що всі імена користувачів різні. Вивести дані про користувачів з довжиною пароля понад 6 символів.
1.7 Створення власного контейнера на базі масиву (додаткове завдання)
Створити узагальнений клас для представлення одновимірного масиву, індекс елементів якого змінюється від
певного значення from до значення to включно. Ці значення можуть бути як додатними,
так і від'ємними. Клас повинен реалізовувати інтерфейс Collection. Доцільно використати клас AbstractList
як базовий.
1.8 Реалізація двобічно зв'язаного списку (додаткове завдання)
Реалізувати узагальнений клас, що представляє двобічно зв'язаний список.
1.9 Реалізація функції видалення елемента з дерева (додаткове завдання)
Додати до прикладу 3.9 функцію видалення визначеного елемента з дерева.
1.10 Реалізація червоно-чорного дерева (завдання підвищеної складності, за вибором студента)
Самостійно реалізувати асоціативний масив на базі червоно-чорного дерева.
2 Методичні вказівки
2.1 Переліки
Починаючи з версії JDK 1.5 (Java 5), реалізовано новий тип-посилання – перелік – список можливих значень, які може отримувати змінна цього типу. У найпростішій своїй формі переліки Java аналогічні відповідним конструкціям C++ і C#.
enum DayOfWeek {
SUNDAY,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY
}
...
DayOfWeek d = DayOfWeek.WEDNESDAY;
Перелічені константи вважаються відкритими (public). Тип enum,
як і клас, може бути відкритим або пакетним. Для імен можливих значень використовують великі літери, оскільки
фактично це константи. З константами зв'язані цілі значення, у попередньому прикладі – відповідно від 0 до
6. Можна отримати ці цілі значення за допомогою функції ordinal(), а ім'я константи – за
допомогою метода name(). Наприклад:
DayOfWeek d = DayOfWeek.WEDNESDAY; System.out.println(d.name() + " " + d.ordinal());
За допомогою статичної функції values() можна отримати масив елементів переліку:
for (int i = 0; i < DayOfWeek.values().length; i++) {
System.out.println(DayOfWeek.values()[i]);
}
Статична функція valueOf() дозволяє отримати елемент переліку за його ім'ям. Наприклад, нам
необхідно отримати ціле значення, пов'язане з певним елементом:
System.out.println(DayOfWeek.valueOf("FRIDAY").ordinal());
У загальному випадку переліки Java надають можливості по визначенню і перевантаженню методів, створенню
додаткових полів тощо. Наприклад, до переліку DayOfWeek можна додати статичну функцію printAll():
static void printAll() {
for (DayOfWeek d : values()) {
System.out.println(d);
}
}
Можна перевантажити виведення переліку через визначення функції toString():
enum Gender {
MALE, FEMALE;
@Override
public String toString() {
switch (this) {
case MALE:
return "чоловіча стать";
case FEMALE:
return "жіноча стать";
}
return "щось неможливе!";
}
}
public class GenderTest {
public static void main(String[] args) {
Gender g = Gender.FEMALE;
System.out.println(g);
}
}
Константи, можна зв'язати з відповідними значеннями. Наприклад, перелік "Супутник Марса" містить поле "Відстань від центру Марса". У нашому прикладі необхідно також додати конструктор та додаткові елементи:
package ua.inf.iwanoff.java.fourth;
enum MoonOfMars {
PHOBOS(9377), DEIMOS(23460);
private double distance;
private MoonOfMars(double distance) {
this.distance = distance;
}
double getDistance() {
return distance;
}
@Override
public String toString() {
return name() + ". " + distance + " km. from Mars";
}
}
public class MoonsOfMarsTest {
public static void main(String[] args) {
MoonOfMars m = MoonOfMars.PHOBOS;
System.out.println(m); // PHOBOS. 9377.0 km from Mars
}
}
Як видно з тексту, наявність конструктора обумовлює опис констант з визначенням фактичних параметрів
2.2 Узагальнення (Generics)
2.2.1 Концепція узагальненого програмування
Часто виникає необхідність у створенні так званих класів-контейнерів – таких, які містять об'єкти довільних типів. При цьому над елементами контейнерів необхідно виконувати деякі однотипні дії. Код для обробки об'єктів різних типів може виглядати практично однаково. Наприклад, якщо для різних типів даних потрібно реалізувати алгоритми на кшталт швидкого сортування або способи обробки таких структур даних, як зв'язаний список або бінарне дерево. У таких випадках код однаковий для всіх типів об'єктів.
Парадигма узагальненого програмування передбачає опис правил зберігання даних і алгоритмів у загальному вигляді незалежно від конкретних типів даних. Конкретні типи даних, над якими виконуються дії, специфікуються пізніше. Механізми розділення структур даних і алгоритмів, а також формування абстрактних описів вимог до даних, визначаються по-різному в різних мовах програмування. Спочатку можливості узагальненого програмування були представлені в сімдесяті роки XX століття мовами CLU й Ада (узагальнені функції), пізніше були реалізовані в мові ML (параметричний поліморфізм).
Найбільш повно і гнучко ідея узагальненого програмування реалізована у мові C++ через механізм шаблонів. Шаблон (template) у C++ – це фрагмент коду, який узагальнено описує роботу з деяким абстрактним типом, заданим як параметр шаблону. Цей фрагмент коду (клас або функція) остаточно компілюється тільки після інстанціювання шаблону конкретним типом, тобто після підставляння конкретного типу замість параметра. На використанні шаблонних функцій і параметризованих класів побудована Стандартна бібліотека шаблонів (STL), що є зараз частиною Стандартної бібліотеки C++. STL включає опис стандартних контейнерних класів і незалежних від них алгоритмів.
Для реалізації узагальненого програмування в Java використовуються узагальнення – спеціальна мовна конструкція, яка з'явилася у синтаксисі мови починаючи з версії Java 5.
2.2.2 Проблеми створення універсальних контейнерів у Java 2
Припустимо, нам необхідно створити контейнер для зберігання пари об'єктів одного типу. Можна запропонувати клас
Pair (пара). Він містить два посилання на клас Object:
public class Pair {
Object first, second;
public Pair(Object first, Object second) {
this.first = first;
this.second = second;
}
}
Оскільки клас Object є базовим для усіх типів-посилань, новий клас можна, наприклад, застосувати
для зберігання пари рядків:
Pair p = new Pair("Прізвище", "Ім\'я");
Такий підхід має певні недоліки:
- Для читання об'єктів необхідно застосувати явне перетворення типів:
String s = (String) p.first; // Замість String s = p.first;
Integer i = (Integer) p.second; // Помилка часу виконання
Pair p1 = new Pair("Прізвище", new Integer(2)); // Жодного повідомлення про помилку
Аналогічні проблеми в Java 2 виникали зі стандартними контейнерними класами. Наслідком реалізованого таким чином підходу стали потенційні помилки часу виконання, які не могли бути знайдені під час компіляції коду.
2.2.3 Синтаксис узагальнень
Зазначені раніше проблеми розв'язує синтаксична конструкція Java 5, так зване узагальнення – конструкція, що містить параметр класу або функції, який містить додаткову інформацію про тип елементів та інших даних. Цей параметр беруть у кутові дужки. Узагальнення надають можливість створення та використання структур даних, безпечних з точки зору типів. Класи, опис яких містить такий параметр, мають назву узагальнених. Під час створення об'єкта узагальненого типу у кутових дужках вказують імена реальних типів. Можна використовувати тільки типи-посилання. Попередній приклад можна реалізувати з застосуванням узагальнень.
public class Pair<T> {
T first, second;
public Pair(T first, T second) {
this.first = first;
this.second = second;
}
public static void main(String[] args) {
Pair<String> p = new Pair<String>("Прізвище", "Ім\'я");
String s = p.first; // Отримуємо рядок без приведення типів
Pair<Integer> p1 = new Pair<Integer>(1, 2); // Можна використовувати цілі константи
int i = p1.second; // Отримуємо ціле значення без приведення типів
}
}
Примітка: Java версії 7 і вище дозволяє не повторювати фактичний параметр узагальнення після імені конструктора. Наприклад:
Pair<Integer> p1 = new Pair<>(1, 2);
Якщо ми намагаємось додати до пари дані різних типів, компілятор згенерує помилку. Помилковою є також спроба явно перетворити тип:
Pair<String> p = new Pair<String>("1", "2");
Integer i = (Integer) p.second; // Помилка компіляції
Тип даних з параметром у кутових дужках (наприклад, Pair<String>) має назву параметризованого
типу.
Узагальнення по зовнішньому представленню і використанню аналогічні шаблонам C++. Але на відміну від шаблонів
C++, існує не декілька різних типів Pair, а один. Фактично у полях класу зберігаються посилання на
Object. Інформація про тип параметрів використовується компілятором для контролю та автоматичного
приведення типів у вихідному тексті.
Окрім узагальнених класів, можна створювати узагальнені інтерфейси. Параметр може бути використаний в описі функцій, оголошених в інтерфейсі. Інтерфейси можуть бути реалізовані як узагальненими, так і неузагальненими класами. Під час їх реалізації замість параметра узагальнення використовують деякий тип-посилання. Наприклад:
interface Function<T> {
T func(T x);
}
class DoubleFunc implements Function<Double> {
@Override
public Double func(Double x) {
return x * 1.5;
}
}
class IntFunc implements Function<Integer> {
@Override
public Integer func(Integer x) {
return x % 2;
}
}
Узагальнені класи та інтерфейси в Java не є ані новими типами, ані шаблонами. Це лише механізм, який вказує компілятору на необхідність подальшої перевірки типів і додавання перетворення типів.
Java також дозволяє створювати узагальнені функції всередині як узагальнених, так і звичайних (неузагальнених) класів:
public class ArrayPrinter {
public static<T> void printArray(T[] a) {
for (T x : a) {
System.out.print(x + "\t");
}
System.out.println();
}
public static void main(String[] args) {
String[] as = {"First", "Second", "Third"};
printArray(as);
Integer[] ai = {1, 2, 4, 8};
printArray(ai);
}
}
Як видно з прикладу, виклик узагальненої функції не вимагає явного визначення типу. Іноді таке визначення необхідне, наприклад, коли в функції немає параметрів узагальненого типу. Якщо це статична функція, необхідно явно вказувати її клас. Наприклад:
public class TypeConverter {
public static <T>T convert(Object object) {
return (T) object;
}
public static void main(String[] args) {
Object o = "Some Text";
String s = TypeConverter.<String>convert(o);
System.out.println(s);
}
}
Рекомендованими іменами формальних параметрів є імена з однієї великої літери. Узагальнення може мати два і більше параметрів. У наведеному нижче прикладі пара може містити посилання на об'єкти різних типів:
public class PairOfDifferentObjects<T, E> {
T first;
E second;
public PairOfDifferentObjects(T first, E second) {
this.first = first;
this.second = second;
}
public static void main(String[] args) {
PairOfDifferentObjects<Integer, String> p =
new PairOfDifferentObjects<Integer, String>(1000, "thousand");
PairOfDifferentObjects<Integer, Integer> p1 =
new PairOfDifferentObjects<Integer, Integer>(1, 2);
//...
}
}
Над даними типу параметра узагальнення можна здійснювати тільки дії, дозволені для об'єктів класу
Object. Іноді для розширення функціональності бажаною є конкретизація типу. Наприклад, ми хочемо
викликати методи, оголошені у певному класі або інтерфейсі. Тоді можна застосувати такий синтаксис опису
параметра: <T extends SomeBaseType> або <T extends FirstType &
SecondType> тощо. Слово extends використовують як для класів, так і для
інтерфейсів.
Наприклад, можна створити узагальнену функцію обчислення середнього арифметичного в масиві деяких числових
значень. Стандартні класи Double, Float, Integer, Long та
інші класи-обгортки числових даних мають загальний абстрактний базовий клас java.lang.Number, що
декларує, зокрема, метод doubleValue(), який дозволяє, отримати число, що зберігається в об'єкті, у
вигляді значення типу double. Цей факт можна використовувати для обчислення
середнього арифметичного. Створена функція може працювати з масивами чисел різних типів:
package ua.inf.iwanoff.java.fourth;
public class AverageTest {
public static<E extends Number> double average(E[] arr) {
double result = 0;
for (E elem : arr) {
result += elem.doubleValue();
}
return result / arr.length;
}
public static void main(String[] args) {
Double[] doubles = { 1.0, 1.1, 1.5 };
System.out.println(average(doubles)); // 1.2
Integer[] ints = { 10, 20, 3, 4 };
System.out.println(average(ints)); // 9.25
}
}
Синтаксис узагальнень передбачає використання так званих масок (wildcard, символ '?'). Маска застосовується, наприклад, для опису посилань на поки невідомий тип. Використання масок робить узагальнені класи та функції більш сумісними. Маска надає альтернативний спосіб створення узагальнених функцій. Такі функції самі по собі не є узагальненими, але містять аргументи узагальнених типів.
Наведемо приклад створення узагальненого класу, який зберігає масив елементів певного типу. Можна також додати статичну функцію виведення на консоль елементів масиву довільного типу, яка демонструє використання масок:
package ua.inf.iwanoff.java.fourth;
public class MyArray<T> {
private T[] arr;
public MyArray(T... arr) {
this.arr = arr;
}
public int size() {
return arr.length;
}
public T get(int i) {
return arr[i];
}
public void set(int i, T t) {
arr[i] = t;
}
public static void printGenericArray(MyArray<?> a) {
for (int i = 0; i < a.size(); i++) {
System.out.print(a.get(i) + "\t");
}
System.out.println();
}
}
В іншому класі здійснюємо тестування:
package ua.inf.iwanoff.java.fourth;
public class MyArrayTest {
public static void main(String[] args) {
MyArray<String> arr1 = new MyArray<>("First", "Second", "Third");
MyArray.printGenericArray(arr1);
MyArray<?> arr2 = new MyArray<>(1, 2, 3); // MyArray<?> замість MyArray<Integer>
MyArray.printGenericArray(arr2);
}
}
Не можна створювати масиви об'єктів узагальнених типів:
T arr = new T[10]; // Помилка!
У нашому прикладі цю проблему можна розв'язати за допомогою посилань на клас Object. Корисною
також буде функція додавання елемента в кінець масиву і видалення останнього елемента. Замість використання
статичної функції printGenericArray() можна перевизначити метод toString().
Альтернативна реалізація може бути такою:
package ua.inf.iwanoff.java.fourth;
import java.util.Arrays;
public class MyArray<T> {
private Object[] arr = {};
public MyArray(T... arr) {
this.arr = arr;
}
public MyArray(int size) {
arr = new Object[size];
}
public int size() {
return arr.length;
}
public T get(int i) {
return (T)arr[i];
}
public void set(int i, T t) {
arr[i] = t;
}
public void add(T t) {
Object[] temp = new Object[arr.length + 1];
System.arraycopy(arr, 0, temp, 0, arr.length);
arr = temp;
arr[arr.length - 1] = t;
}
public void remove(int i) {
Object[] temp = new Object[arr.length - 1];
System.arraycopy(arr, 0, temp, 0, i);
System.arraycopy(arr, i + 1, temp, i, arr.length - i - 1);
arr = temp;
}
@Override
public String toString() {
return Arrays.toString(arr);
}
}
В новому класі здійснюємо тестування:
package ua.inf.iwanoff.java.fourth;
public class TestClass {
public static void main(String[] args) {
MyArray<String> a = new MyArray<>("1", "2");
String s = a.get(a.size() - 1);
System.out.println(s); // 2
a.set(1, "New");
System.out.println(a); // 1 New
MyArray<Double> b = new MyArray<>(3);
b.set(0, 1.0);
b.set(1, 2.0);
b.set(2, 4.0);
b.remove(2);
b.add(8.0);
System.out.println(b); // [1.0, 2.0, 8.0]
}
}
Функціональність класу можна розширити методами додавання нового елемента всередині масиву, видалення всіх елементів тощо.
Можна обмежити використання типу параметра функції певними похідними класами, наприклад, MyArray<? super
String>. Тоді використання списку MyArray<Integer> неможливе.
2.2.4 Використання класу Optional
Як приклад стандартного узагальненого класу можна навести клас Optional.
Опціональні значення – це контейнери для значень, які можуть іноді бути порожніми. Традиційно для невизначених
величин використовували значення null. Використання константи
null може бути незручним, оскільки воно може призвести до генерації винятку
NullPointerException, що ускладнює налагодження і супровід програми.
Узагальнений клас Optional дозволяє зберегти значення посилання на деякий об'єкт, а також
перевірити, чи встановлено значення. Наприклад, деякий метод повертає числове значення, але для деяких значень
аргументу не може повернути щось певне. Такий метод може повернути об'єкт типу Optional і це
значення потім може бути використано у місці виклику. Припустимо, деяка функція обчислює і повертає зворотну
величину і повертає "порожній" об'єкт, якщо
аргумент дорівнює 0. У функції main() здійснюємо обчислення зворотних величин для чисел з масиву:
package ua.inf.iwanoff.java.fourth;
import java.util.Optional;
public class OptionalDemo {
static Optional<Double> reciprocal(double x) {
Optional<Double> result = Optional.empty();
if (x != 0) {
result = Optional.of(1 / x);
}
return result;
}
public static void main(String[] args) {
double[] arr = { -2, 0, 10 };
Optional<Double> y;
for (double x : arr) {
System.out.printf("x = %6.3f ", x);
y = reciprocal(x);
if (y.isPresent()) {
System.out.printf("y = %6.3f%n", y.get());
}
else {
System.out.printf("Значення не може бути розраховане%n");
}
}
}
}
Якщо не здійснювати перевірку на наявність значення (isPresent()), при спробі виклику функції
get() для "порожнього" значення
буде згенеровано виняток java.util.NoSuchElementException. Його можна перехоплювати замість виклику
функції isPresent().
У деяких випадках значення null не повинно зберігатися як можливе допустиме. В
цьому випадку для збереження значення слід використовувати ofNullable(). Наприклад:
Integer k = null; Optional<Integer> opt = Optional.ofNullable(k); System.out.println(opt.isPresent()); // false
Припустимо, якщо описана раніше функція reciprocal() не повертає значення в разі ділення на нуль,
змінній y слід присвоїти 0. Традиційно в цьому випадку використовують конструкцію if
... else або умовну операцію:
y = reciprocal(x); double z = y.isPresent() ? y.get() : 0;
Метод orElse() дозволяє зробити код більш компактним:
double z = reciprocal(x).orElse(0.0);
Крім узагальненого класу Optional можна також використовувати класи, оптимізовані для примітивних
типів – OptionalInt, OptionalLong, OptionalBoolean тощо. Попередній приклад з
обчисленням зворотної величини можна було б реалізувати таким чином (з використанням OptionalDouble):
package ua.inf.iwanoff.java.fourth;
import java.util.OptionalDouble;
public class OptionalDoubleDemo {
static OptionalDouble reciprocal(double x) {
OptionalDouble result = OptionalDouble.empty();
if (x != 0) {
result = OptionalDouble.of(1 / x);
}
return result;
}
public static void main(String[] args) {
double[] arr = {-2, 0, 10};
OptionalDouble y;
for (double x : arr) {
System.out.printf("x = %6.3f ", x);
y = reciprocal(x);
if (y.isPresent()) {
System.out.printf("y = %6.3f%n", y.getAsDouble());
}
else {
System.out.printf("Значення не може бути розраховане%n");
}
}
}
}
Як видно з прикладу, результат слід отримувати за допомогою методу getAsDouble() замість get().
2.3 Контейнерні класи та інтерфейси. Робота зі списками
2.3.1 Загальні відомості
Засоби Java для роботи з колекціями надають уніфіковану архітектуру для представлення та управління наборами даних. Ця архітектура дозволяє працювати з колекціями незалежно від деталей їхньої внутрішньої організації. Засоби для роботи з колекціями включають більше десятка інтерфейсів, а також стандартні реалізації цих інтерфейсів і набір алгоритмів для роботи з ними.
Колекція – це об'єкт, який представляє групу об'єктів. Використання колекцій забезпечує підвищення ефективності програм завдяки використанню високоефективних алгоритмів, а також сприяє створенню коду, придатного для повторного використання. Основними елементами засобів роботи з колекціями є такі:
- інтерфейси
- стандартні реалізації інтерфейсів
- алгоритми
- утиліти для роботи з масивами
Крім того, Java 8 підтримує контейнери Java 1.1. Це Vector, Enumeration,
Stack, BitSet і деякі інші. Наприклад, клас Vector надає
функціональність, аналогічну ArrayList. У першій версії Java ці контейнери не забезпечували
стандартизованого інтерфейсу. Вони також не дозволяють користувачеві відмовитися від надмірної синхронізації,
яка актуальна лише в багатопотоковому оточенні, і отже, недостатньо ефективні. Внаслідок цього вони вважаються
застарілими та не рекомендовані для використання. Замість них слід використовувати відповідні узагальнені
контейнери Java 5.
Стандартні контейнерні класи Java дозволяють зберігати в колекції посилання на об'єкти, класи яких походять від
класу Object. Контейнерні класи реалізовані в пакеті java.util. Починаючи з Java 5,
усі контейнерні класи реалізовані як узагальнені.
Існує два базових інтерфейси, в яких декларована функціональність контейнерних класів: Collection
(похідний від Iterable) і Map. Інтерфейс Collection є базовим для
інтерфейсів List (список), Set (множина), Queue (черга) і
Deque (черга з двома кінцями).
Інтерфейс List (список) описує пронумеровану колекцію (послідовність), елементи якої можуть
повторюватися.
Інтерфейс Set реалізований класами HashSet і LinkedHashSet. Інтерфейс
SortedSet, похідний від Set, реалізований класом TreeSet. Інтерфейс
Map реалізований класом HashMap. Інтерфейс SortedMap, похідний від Map,
реалізований класом TreeMap.
Класи HashSet, LinkedHashSet і HashMap використовують для ідентифікації
елементів так звані хеш-коди. Хеш-код – це унікальна послідовність бітів фіксованої довжини. Для
кожного об'єкта ця послідовність вважається унікальною. Хеш-коди забезпечують швидкий доступ до даних за деяким
ключем. Механізм одержання хеш-кодів забезпечує їх майже повну унікальність. Усі об'єкти Java можуть генерувати
хеш-коди: метод hashCode() визначений для класу Object.
Для більшості колекцій існують як "звичайні" реалізації, так і реалізації, безпечні з точки зору
потоків управління, наприклад CopyOnWriteArrayList, ArrayBlockingQueue тощо.
2.3.2 Інтерфейс Collection
Інтерфейс Collection є базовим для багатьох інтерфейсів Collection Framework і оголошує найбільш
загальні методи колекцій:
| Метод | Опис |
|---|---|
int size() |
Повертає розмір колекції |
boolean isEmpty() |
Повертає true, якщо колекція порожня |
boolean contains(Object o) |
Повертає true, якщо колекція містить об'єкт |
Iterator<E> iterator() |
Повертає ітератор – об'єкт, який послідовно вказує на елементи |
Object[] toArray() |
Повертає масив посилань на Object, який містить копії всіх елементів колекції |
<T> T[] toArray(T[] a) |
Повертає масив посилань на T, який містить копії всіх елементів колекції |
boolean add(E e) |
Додає об'єкт у колекцію. Повертає true, якщо об'єкт доданий |
boolean remove(Object o) |
Видаляє об'єкт з колекції |
boolean containsAll(Collection<?> c) |
Повертає true якщо колекція містить іншу
колекцію
|
boolean addAll(Collection<? extends E> c) |
Додає об'єкти в колекцію. Повертає true, якщо об'єкти додані |
boolean removeAll(Collection<?> c) |
Видаляє об'єкти з колекції |
boolean retainAll(Collection<?> c) |
Залишає об'єкти, присутні в іншій колекції |
void clear() |
Видаляє всі елементи з колекції |
Примітка: в таблиці не вказані методи з усталеною реалізацією, які були додані у Java 8.
Наведений нижче приклад демонструє роботу методів інтерфейсу. В прикладі використовується клас
ArrayList як найпростіша реалізація інтерфейсу Collection:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class CollectionDemo {
public static void main(String[] args) {
Collection<Integer> c = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5));
System.out.println(c.size()); // 5
System.out.println(c.isEmpty()); // false
System.out.println(c.contains(4)); // true
c.add(6);
System.out.println(c); // [1, 2, 3, 4, 5, 6]
c.remove(1);
System.out.println(c); // [2, 3, 4, 5, 6]
Collection<Integer> c1 = new ArrayList<>(Arrays.asList(3, 4));
System.out.println(c.containsAll(c1));// true
c.addAll(c1);
System.out.println(c); // [2, 3, 4, 5, 6, 3, 4]
Collection<Integer> c2 = new ArrayList<>(c); // копія
c.removeAll(c1);
System.out.println(c); // [2, 5, 6]
c2.retainAll(c1);
System.out.println(c2); // [3, 4, 3, 4]
c.clear();
System.out.println(c); // []
}
}
2.3.3 Робота зі списками
Інтерфейс List описує упорядковану колекцію (послідовність). Цей інтерфейс реалізують стандартні
класи ArrayList і LinkedList. Клас ArrayList реалізує список за допомогою
масиву змінної довжини. Клас LinkedList зберігає об'єкти за допомогою так званого зв'язаного
списку.
Існує також стандартна абстрактна реалізація списку – клас AbstractList. Цей клас, похідний
від AbstractCollection, надає низку корисних засобів. Практично в тій чи іншій формі реалізовані
всі методи, крім get() і size(). Проте, для конкретної реалізації списку більшість
функцій слід перекрити. Клас AbstractList – базовий для ArrayList. Клас AbstractSequentialList,
похідний від AbstractList, є базовим для класу LinkedList.
Створити порожній список посилань на об'єкти деякого типу (SomeType) можна за допомогою усталеного
конструктора:
List<SomeType> al = new ArrayList<SomeType>();
Можна також одразу описати посилання на ArrayList:
ArrayList<SomeType> al = new ArrayList<SomeType>();
Другий варіант іноді не є бажаним, оскільки в такому випадку знижується гнучкість програми. Перший варіант
дозволить легко замінити реалізацію списку ArrayList на будь-яку іншу реалізацію інтерфейсу List,
яка більше відповідає вимогам конкретної задачі. У другому випадку є спокуса викликати методи, специфічні для
ArrayList, тому перехід на іншу реалізацію буде ускладнено.
Об'єкт класу ArrayList містить масив elementData елементів типу Object.
Фізичний розмір масиву (capacity), якщо не викликати конструктор з явним зазначенням цього розміру, усталено
дорівнює 10. Кожне додавання елемента передбачає виклик внутрішнього методу ensureCapacity(), який
в разі заповнення масиву здійснює створення нового масиву з копіюванням в нього наявних елементів. Розмір нового
масиву обчислюється за формулою (старий_розмір * 3) / 2 + 1.
Під час видалення елементів фізичний розмір масиву не зменшується. Для заощадження пам'яті після багаторазового
видалення елементів доцільно викликати метод trimToSize().
Створивши порожній список, у нього можна додавати елементи за допомогою функції add(). Метод
add() з одним аргументом типу-посилання додає елемент у кінець списку. Якщо цю функцію викликати з
двома аргументами, новий елемент буде додано в список у позиції, зазначеній першим параметром:
List<String> al = new ArrayList<String>();
al.add("abc");
al.add("def");
al.add("xyz");
al.add(2, "ghi"); // Додавання нового рядка перед "xyz"
До списку можна додати всі елементи іншого списку (або іншої колекції) за допомогою функції
addAll().
Можна створити новий список із використанням наявного. Новий список містить посилання на копії елементів. Наприклад:
List<String> a11 = new ArrayList<String>(al);
За допомогою статичної функції asList() класу java.util.Arrays можна створити список
з наявного масиву. Масив можна також створити безпосередньо у списку параметрів функції. Наприклад:
String[] arr = {"one", "two", "three"};
List<String> a2 = Arrays.asList(arr);
List<String> a3 = Arrays.asList("four", "five");
Для списків перевантажена функція toString(), яка дозволяє, наприклад, вивести всі елементи масиву
на екран без використання циклів. Елементи виводяться у квадратних дужках:
System.out.println(a3); // [four, five]
Списки дозволяють роботу з окремими елементами. Метод size() повертає кількість елементів, що
містяться в списку. Як і в масивах, доступ до елементів списків може здійснюватися за індексом, але не через
операцію [], а за допомогою методів get() і set(). Метод
get() класу ArrayList повертає елемент із зазначеним індексом (позиція в списку). Як і
елементи масивів, елементи списків пронумеровані з нуля. У наведеному нижче прикладі рядки виводяться за
допомогою функції println():
List<String> al = new ArrayList<String>();
al.add("abc");
al.add("def");
al.add("xyz");
for (int i = 0; i < al.size(); i++) {
System.out.println(al.get(i));
}
Метод set() дозволяє змінити об'єкт, що зберігається в зазначеній позиції. Метод
remove() видаляє об'єкт у зазначеній позиції:
al.set(0, "new"); al.remove(2); System.out.println(al); // [new, def]
Функція subList(fromIndex, toIndex) повертає список, складений з елементів починаючи з елемента з
індексом fromIndex і не включаючи елемент з індексом toIndex. Наприклад:
System.out.println(al.subList(1, 3)); // [def, xyz]
Метод removeRange(m, n) видаляє всі елементи, індекс яких між m включно та не
включаючи n. Усі елементи колекцій віддаляються за допомогою методу clear(). Функція
contains() повертає true, якщо список містить зазначений елемент. Наприклад:
if (al.contains("abc")) {
System.out.println(al);
}
Функція toArray() повертає посилання на масив копій об'єктів, посилання на які зберігаються в
списку.
Object [] a = al.toArray(); System.out.println(a[1]); // def (al.toArray()) [2] = "text"; // Зміна елементів нового масиву
Для збереження цілих і дійсних значень у колекціях часто використовують класи-оболонки Integer та
Double відповідно.
У тих випадках, коли частіше, ніж вибір довільного елемента, застосовують операції додавання і видалення
елементів у довільних місцях, доцільно використовувати клас LinkedList, що зберігає об'єкти за
допомогою зв'язаного списку. Зв'язний список, реалізований у Java контейнером LinkedList,
є двобічно зв'язаним списком, де кожен елемент містить посилання на попередній і наступний елементи.
Для зручної роботи додані також методи addFirst(), addLast(),
removeFirst() і removeLast().
LinkedList<String> list = new LinkedList<String>();
list.addLast("last"); // Те саме, що list.add("last");
list.addFirst("first");
System.out.println(list); // [first, last]
list.removeFirst();
list.removeLast();
System.out.println(list); // []
Ці специфічні функції додані саме в LinkedList, оскільки вони не можуть бути ефективно реалізовані
в ArrayList із застосуванням масивів.
Зв'язані списки у Java підтримують роботу з окремими елементами, але ці функції не можуть бути реалізовані ефективно.
2.3.4 Ітератори
Для проходження по колекції (списку) об'єктів використовується ітератор – спеціальний допоміжний об'єкт.
Як і самі контейнери, ітератори базуються на інтерфейсі. Інтерфейс Iterator, визначений у пакеті
java.utіl. Будь-який ітератор має три методи:
boolean hasNext(); // перевіряє, чи є ще елементи в контейнері,
// та повертає true, якщо ще є елементи послідовності.
Object next(); // повертає посилання на наступний елемент
void remove(); // видаляє останній обраний елемент (на який посилається ітератор)
Після першого виклику методу next() ітератор указуватиме на початковий елемент контейнера.
Колекції Java повертають об'єкт-ітератор за допомогою методу iterator():
List<String> s = new ArrayList<String>();
s.add("First");
s.add("Second");
for (Iterator<String> i = s.iterator(); i.hasNext(); ) {
System.out.println(i.next());
}
Як видно з наведеного прикладу, ітератор теж є узагальненим типом.
Альтернативна форма циклу for (for each) дозволяє обійти список без явного створення
ітератора:
List<Integer> a = new ArrayList<Integer>();
a.add(1);
a.add(2);
a.add(3);
a.add(4);
for (Integer i : a) {
System.out.print(i + " ");
}
Як і для масивів, альтернативна форма циклу for не дозволяє змінювати значення
елементів, або видаляти їх.
Спеціальний вид ітератора списку, ListIterator, надає додаткові можливості ітерації, зокрема,
проходження по списку у зворотному порядку. В наведеному нижче прикладі для перевірки, чи є слово паліндромом
використовується список символів і ListIterator, який забезпечує проходження у зворотному порядку:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class ListIteratorTest {
public static void main(String[] args) {
String palStr = "racecar";
List<Character> palindrome = new LinkedList<Character>();
for (char ch : palStr.toCharArray()) {
palindrome.add(ch);
}
System.out.println("Input string is: " + palStr);
ListIterator<Character> iterator = palindrome.listIterator();
ListIterator<Character> revIterator = palindrome.listIterator(palindrome.size());
boolean result = true;
while (revIterator.hasPrevious() && iterator.hasNext()) {
if (iterator.next() != revIterator.previous()) {
result = false;
break;
}
}
if (result) {
System.out.print("Input string is a palindrome");
}
else {
System.out.print("Input string is not a palindrome");
}
}
}
2.3.5 Додаткові можливості роботи з колекціями
Починаючи з Java 8, стандартні інтерфейси пакету java.util доповнені методами, орієнтованими на
використання лямбда-виразів і посилань на методи. Для забезпечення сумісності з попередніми версіями Java нові
методи інтерфейсів представлені з усталеною реалізацією. Зокрема, інтерфейс Iterable визначає метод
forEach(), який дозволяє виконати в циклі деякі дії, що не змінюють елементів колекції. Дію можна
задати лямбда-виразом або посиланням на метод. Наприклад:
public class ForEachDemo {
static int sum = 0;
public static void main(String[] args) {
Iterable<Integer> numbers = new ArrayList(Arrays.asList(2, 3, 4));
numbers.forEach(n -> sum += n);
System.out.println(sum);
}
}
У наведеному вище прикладі здійснюється сумування елементів колекції. Змінна-сума описана як статичне поле класу, оскільки лямбда-вирази не можуть змінювати локальні змінні.
Інтерфейс Collection визначає метод removeIf(), який дозволяє видалити з колекції
дані, відповідні деякому правилу-фільтру. У наведеному нижче прикладі з колекції цілих чисел видаляються непарні
елементи. Метод forEach() використовується для виведення елементів колекції в стовпчик:
Collection<Integer> c = new ArrayList(Arrays.asList(2, 4, 11, 8, 12, 3)); c.removeIf(k -> k % 2 != 0); // Решта елементів виводиться в стовпчик: c.forEach(System.out::println);
Інтерфейс List надає методи replaceAll() і sort(). Останній можна
використовувати замість аналогічного статичного методу класу Collections, проте визначення ознаки
сортування є обов'язковим:
List<Integer> list = new ArrayList(Arrays.asList(2, 4, 11, 8, 12, 3)); list.replaceAll(k -> k * k); // замінюємо числа їхніми квадратами System.out.println(list); // [4, 16, 121, 64, 144, 9] list.sort(Integer::compare); System.out.println(list); // [4, 9, 16, 64, 121, 144] list.sort((i1, i2) -> Integer.compare(i2, i1)); System.out.println(list); // [144, 121, 64, 16, 9, 4]
2.4 Робота з чергами та стеками
Черга в широкому сенсі є структурою даних, яку заповнюють поелементно, та отримують з неї об'єкти за певним правилом. У вузькому сенсі цим правилом є "першим прийшов – першим вийшов" (FIFO, First In – First Out). У черзі, організованій за принципом FIFO, додавання елемента можливо лише в кінець черги, отримання – тільки з початку черги.
У бібліотеці контейнерів черга представлена інтерфейсом Queue. Методи, оголошені в цьому
інтерфейсі, наведені в таблиці:
| Тип операції | Генерує виняток | Повертає спеціальне значення |
|---|---|---|
| Додавання | add(e) |
offer(e) |
| Видалення з отриманням елемента | remove() |
poll() |
| Отримання елемента без видалення | element() |
peek() |
Метод offer() повертає false, якщо не вдалося додати елемент, наприклад, якщо
реалізована черга з обмеженою кількістю елементів. У цьому випадку метод add() генерує виняток.
Аналогічно remove() і element() генерують виняток, якщо черга порожня, а
poll() і peek() в цьому випадку повертають null.
Для реалізації черги найзручніше використовувати клас LinkedList, який реалізує інтерфейс Queue.
Наприклад:
package ua.inf.iwanoff.java.fourth;
import java.util.LinkedList;
import java.util.Queue;
public class SimpleQueueTest {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<>();
queue.add("First");
queue.add("Second");
queue.add("Third");
queue.add("Fourth");
String s;
while ((s = queue.poll()) != null) {
System.out.print(s + " "); // First Second Third Fourth
}
}
}
Клас PriorityQueue впорядковує елементи відповідно до компаратора (об'єкта класу, що реалізує
інтерфейс Comparator), заданого в конструкторі як параметр. Якщо об'єкт створити за допомогою
конструктора без параметрів, елементи будуть упорядковані в природному порядку (для чисел – за зростанням,
для рядків – за абеткою). Наприклад:
package ua.inf.iwanoff.java.fourth;
import java.util.PriorityQueue;
import java.util.Queue;
public class PriorityQueueTest {
public static void main(String[] args) {
Queue<String> queue = new PriorityQueue<>();
queue.add("First");
queue.add("Second");
queue.add("Third");
queue.add("Fourth");
String s;
while ((s = queue.poll()) != null) {
System.out.print(s + " "); // First Fourth Second Third
}
}
}
Інтерфейс Deque (дек, double-ended-queue) надає можливість додавати й видаляти елементи з обох
кінців. Методи, оголошені в цьому інтерфейсі, наведені в таблиці:
| Тип операції | Робота з першим елементом | Робота з останнім елементом |
|---|---|---|
| Додавання | addFirst(e) |
addLast(e) |
| Видалення з отриманням елемента | removeFirst() |
removeLast() |
| Отримання елемента без видалення | getFirst() |
getLast() |
Кожна з пар представляє відповідно функцію, яка генерує виняток, і функцію, яка повертає спеціальне значення. Є
також методи, що дозволяють видалити перше або останнє входження заданого елемента
(removeFirstOccurrence() і removeLastOccurrence() відповідно).
Для реалізації інтерфейсу можна використовувати спеціальний клас ArrayDeque, або зв'язний список (LinkedList).
Стек – це структура даних, організована за принципом "останній прийшов – перший вийшов" (LIFO, last in – first out). Можливі три операції зі стеком: додавання елементу (push), видалення елементу (pop) і читання головного елемента (peek).
У JRE 1.1 стек представлений класом Stack. Наприклад:
package ua.inf.iwanoff.java.fourth;
import java.util.Stack;
public class StackTest {
public static void main(String[] args) {
Stack<String> stack = new Stack<>();
stack.push("First");
stack.push("Second");
stack.push("Third");
stack.push("Fourth");
String s;
while (!stack.isEmpty()) {
s = stack.pop();
System.out.print(s + " "); // Fourth Third Second First
}
}
}
Цей клас зараз не рекомендований до використання. Замість нього можна використовувати інтерфейс Deque,
який оголошує аналогічні методи. Наприклад:
package ua.inf.iwanoff.java.fourth;
import java.util.ArrayDeque;
import java.util.Deque;
public class AnotherStackTest {
public static void main(String[] args) {
Deque<String> stack = new ArrayDeque<>();
stack.push("First");
stack.push("Second");
stack.push("Third");
stack.push("Fourth");
String s;
while (!stack.isEmpty()) {
s = stack.pop();
System.out.print(s + " "); // Fourth Third Second First
}
}
}
Стеки часто використовуються в різних алгоритмах. Зокрема, за допомогою стеку в деяких задачах можна позбутися рекурсії.
2.5 Статичні методи класу Collections. Алгоритми
2.5.1 Створення спеціальних контейнерів з використанням класу Collections
Як клас Arrays для масивів, для колекцій існує допоміжний клас Collections. Цей клас
надає низку функцій для роботи з колекціями, зокрема зі списками. Велика група функцій призначена для створення
колекцій різних типів. Наведений нижче приклад демонструє створення колекцій за допомогою статичних методів
класу Collections: відповідно, порожнього списку (emptyList()), "одинака"
(singletonList()) і списку тільки для читання зі звичайного (unmodifiableList()) або
колекції тільки для читання (unmodifiableCollection()):
import java.util.*;
public class CollectionsCreationDemo {
public static void main(String[] args) {
List<Integer> emptyList = Collections.emptyList();
System.out.println(emptyList); // []
List<Integer> singletonList = Collections.singletonList(10);
System.out.println(singletonList); // [10]
List<Integer> list = new ArrayList<>(Arrays.<Integer>asList(1, 2, 3));
List<Integer> unmodifiableList = Collections.unmodifiableList(list);
Collection<Integer> collection = Collections.unmodifiableCollection(list);
}
}
Всі наведені вище функції створюють набори даних тільки для читання.
Аналогічно працюють методи, що створюють відповідні множини – emptySet(), singleton(),
unmodifiableSet().
2.5.2 Алгоритми
Під алгоритмом в бібліотеці колекцій слід розуміти деяку функцію, що реалізує роботу з колекцією (отримання певного результату або перетворення елементів колекції). В Java Collections API ця функція як правило, статична й узагальнена.
Як і клас Arrays, клас Collections містить реалізацію статичних функцій
sort() та fill() з аналогічними правилами застосування. Окрім того, є велика кількість
статичних функцій, які дозволяють обробляти списки без застосування циклів. Це, наприклад, такі функції, як
max() (пошук максимального елемента), min() (пошук мінімального елемента), indexOfSubList()
(пошук індексу першого повного входження підсписку у список), frequency() (визначення кількості
разів входження певного елемента у список), reverse() (заміна порядку елементів на протилежний),
rotate() (циклічний зсув списку на задану кількість елементів), shuffle() ("тасування"
елементів), nCopies() (створення нового списку з визначеною кількістю однакових елементів).
Використання цих функцій можна проілюструвати на наведеному нижче прикладі:
List<Integer> a = Arrays.asList(0, 1, 2, 3, 3, -4); System.out.println(Collections.max(a)); // 3 System.out.println(Collections.min(a)); // -4 System.out.println(Collections.frequency(a, 2)); // 1 раз System.out.println(Collections.frequency(a, 3)); // 2 рази Collections.reverse(a); // змінюємо порядок елементів на протилежний System.out.println(a); // [-4, 3, 3, 2, 1, 0] Collections.rotate(a, 3); // зсуває список циклічно на 3 елементи System.out.println(a); // [2, 1, 0, -4, 3, 3] List<Integer> sublist = Collections.nCopies(2, 3); // новий список містить 2 трійки System.out.println(Collections.indexOfSubList(a, sublist)); // 4 Collections.shuffle(a); // "тасуємо" елементи System.out.println(a); // елементи в довільному порядку Collections.sort(a); System.out.println(a); // [-4, 0, 1, 2, 3, 3] List<Integer> b = new ArrayList<Integer>(a); Collections.fill(b, 8); System.out.println(b); // [8, 8, 8, 8, 8, 8] Collections.copy(b, a); System.out.println(b); // [-4, 0, 1, 2, 3, 3] System.out.println(Collections.binarySearch(b, 2)); // 3 Collections.swap(b, 0, 5); System.out.println(b); // [3, 0, 1, 2, 3, -4] Collections.replaceAll(b, 3, 10); System.out.println(b); // [10, 0, 1, 2, 10, -4]
Клас Collections також надає методи спеціально для роботи зі списками, отримання першого й
останнього індексу початку входження підсписку в список (indexOfSubList(), lastIndexOfSubList())
тощо.
2.6 Робота з множинами та асоціативними масивами
2.6.1 Множини
Множина – це колекція, що не містить однакових елементів. Три основних реалізації інтерфейсу
Set – HashSet, LinkedHashSet і TreeSet. Як і списки, множини
є узагальненими типами. Класи HashSet і LinkedHashSet використовують хеш-коди для
ідентифікації елемента. Клас TreeSet використовує двійкове дерево для збереження елементів і
гарантує їх певний порядок.
Метод add() додає елемент до множини і повертає true якщо елемент раніше був
відсутній. В іншому випадку елемент не додається, а метод add() повертає false.
Усі елементи множини видаляються за допомогою методу clear().
Set<String> s = new HashSet<String>();
System.out.println(s.add("First")); // true
System.out.println(s.add("Second")); // true
System.out.println(s.add("First")); // false
System.out.println(s); // [First, Second]
s.clear();
System.out.println(s); // []
Метод remove() видаляє зазначений елемент множини, якщо такий є. Метод contains()
повертає true, якщо множина містить зазначений елемент.
У наведеному нижче прикладі до множини цілих чисел додається десять випадкових значень у діапазоні від -9 до 9:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class SetOfIntegers {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<Integer>();
Random random = new Random();
for (int i = 0; i < 10; i++) {
Integer k = random.nextInt() % 10;
set.add(k);
}
System.out.println(set);
}
}
Вислідна множина як правило, містить менш ніж 10 чисел, оскільки окремі значення можуть повторюватися.
Оскільки ми використовуємо TreeSet, числа зберігаються та виводяться в упорядкованому (за
зростанням) вигляді. Для того, щоб додати саме десять різних чисел, програму можна модифікувати, наприклад із
застосуванням циклу while замість for:
while (set.size() < 10) {
. . .
}
Можна створити масив, який містить копії елементів множини. В такий спосіб можна звертатися до елементів за індексом. Наприклад, так можна вивести елементи множини у зворотному порядку:
Set<Integer> set = new HashSet<>(Arrays.asList(1, 2, 4));
Object[] arr = set.toArray();
for (int i = set.size() - 1; i >= 0; i--) {
System.out.println(arr[i]);
}
Оскільки множина може містити тільки різні елементи, її можна використати для підрахунку різних слів, літер,
цифр тощо – створюється множина та викликається метод size(). Застосовуючи
TreeSet, можна виводити слова та літери в алфавітному порядку. У наведеному нижче прикладі
вводиться речення та виводяться всі різні літери речення (не враховуючи роздільників) в алфавітному порядку:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class Sentence {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// Функція nextLine() читає рядок до кінця:
String sentence = scanner.nextLine();
// Створюємо множину роздільників:
Set<Character> delimiters = new HashSet<Character>(
Arrays.asList(' ', '.', ',', ':', ';', '?', '!', '-', '(', ')', '\"'));
// Створюємо множину літер:
Set<Character> letters = new TreeSet<Character>();
// Додаємо всі літери крім роздільників:
for (int i = 0; i < sentence.length(); i++) {
if (!delimiters.contains(sentence.charAt(i))) {
letters.add(sentence.charAt(i));
}
}
System.out.println(letters);
}
}
Порядок сортування елементів TreeSet можна задати, реалізувавши інтерфейс Comparable,
або передавши в конструктор TreeSet посилання на об'єкт класу, який реалізує інтерфейс
Comparator. Наприклад, так можна відсортувати дерево у зворотному порядку:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class CompTest {
public static void main(String args[]) {
TreeSet<String> ts = new TreeSet<String>(new Comparator<String>()
{
@Override
public int compare(String s1, String s2) {
return s2.compareTo(s1);
}
});
ts.add("C");
ts.add("E");
ts.add("D");
ts.add("B");
ts.add("A");
ts.add("F");
for (String element : ts)
System.out.print(element + " ");
}
}
}
2.6.2 Робота з асоціативними масивами
Асоціативні масиви можуть зберігати пари посилань на об'єкти. Асоціативні масиви теж є узагальненими
типами. Асоціативні масиви у Java представлені узагальненим інтерфейсом Map, який реалізовано,
зокрема, класом HashMap. Інтерфейс SortedMap, похідний від Map, вимагає
впорядкованого за ключем зберігання пар. Інтерфейс NavigableMap, що з'явився в Java SE 6, розширює
SortedМap і додає нові можливості пошуку за ключем. Цей інтерфейс реалізовано класом
TreeMap.
Кожне значення (об'єкт), яке зберігається в асоціативному масиві, зв'язується з конкретним значенням іншого
об'єкта (ключа). Метод put(key, value) додає значення (value) і асоціює з ним ключ
(key). Якщо асоціативний масив раніше містив пари з вказаним ключем, нове значення заміщає старе.
Метод put() повертає попереднє значення, пов'язане з ключем, або null, якщо
ключ був відсутній. Метод get(Object key) повертає по об'єкт за заданим ключем. Для перевірки
знаходження ключа та значення застосовуються методи containsKey() і containsValue().
На логічному рівні можна представити асоціативний масив через три допоміжні колекції:
keySet– множина значень ключа;values– список значень;entrySet– множина пар ключ-значення.
Через відповідні функції keySet(), values() та entrySet() можна
здійснювати певні дії, в першу чергу послідовне проходження елементів.
У наведеному нижче прикладі обчислюється кількість входжень різних слів у речення. Слова і відповідні кількості
зберігаються в асоціативному масиві. Використання класу TreeMap гарантує алфавітний порядок слів
(ключів).
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class WordsCounter {
public static void main(String[] args) {
Map<String, Integer> m = new TreeMap<String, Integer>();
String s = "the first men on the moon";
StringTokenizer st = new StringTokenizer(s);
while (st.hasMoreTokens()) {
String word = st.nextToken();
Integer count = m.get(word);
m.put(word, (count == null) ? 1 : count + 1);
}
for (String word : m.keySet()) {
System.out.println(word + " " + m.get(word));
}
}
}
Використання keySet() передбачає окремий пошук кожного значення за ключем. Більш рекомендованим є
обхід асоціативного масиву через множину пар:
for (Map.Entry<?, ?> entry : m.entrySet())
System.out.println(entry.getKey() + " " + entry.getValue());
Тут метод entrySet() дозволяє одержати представлення асоціативного масиву у вигляді колекції
Set.
Порядок сортування елементів TreeMap також можна змінити, вказавши як параметр конструктора TreeMap
об'єкт класу, який реалізує інтерфейс Comparator, або задавши ключ як об'єкт класу, який реалізує
інтерфейс Comparable:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class TreeMapKey implements Comparable<TreeMapKey> {
private String name;
public String getName() {
return name;
}
public TreeMapKey(String name) {
super();
this.name = name;
}
@Override
public int compareTo(TreeMapKey o) {
return name.substring(o.getName().indexOf(" ")).trim()
.compareToIgnoreCase(o.getName().substring(o.getName().indexOf(" ")).trim());
}
public static void main(String args[]) {
TreeMap<TreeMapKey, Integer> tm = new TreeMap<TreeMapKey, Integer>();
tm.put(new TreeMapKey("Петро Іванов"), new Integer(1982));
tm.put(new TreeMapKey("Іван Петров"), new Integer(1979));
tm.put(new TreeMapKey("Василь Сидоров"), new Integer(1988));
tm.put(new TreeMapKey("Сидір Васильєв"), new Integer(1980));
for (Map.Entry<TreeMapKey, Integer> me : tm.entrySet()) {
System.out.print(me.getKey().getName() + ": ");
System.out.println(me.getValue());
}
System.out.println();
}
}
Клас Hashtable – одна з реалізацій інтерфейсу Map. Hashtable крім
розміру має місткість (розмір буфера, виділеного під елементи масиву). Крім цього він характеризується показником
завантаженості – часткою буфера, після заповнення якої місткість автоматично збільшується. Конструктор Hashtable()
без параметрів створює порожній об'єкт з місткістю в 101 елемент і показником завантаженості 0.75.
Клас Properties, похідний від Hashtable, замість пар довільних об'єктів зберігає
пари рядків. Якщо в конкретній задачі й ключі й значення елементів асоціативного масиву мають тип
String, зручніше скористатися класом Properties. У класі Properties
визначені методи getProperty(String key) і setProperty(String key, String value).
Починаючи з Java 8, до інтерфейсу Map додані методи, наведені в таблиці:
| Метод | Опис |
|---|---|
V getOrDefault(Object key, V& defaultValue) |
Повертає значення, або усталене значення, якщо ключ відсутній |
V putIfAbsent(K key, V value) |
Додає пару, якщо ключ відсутній, і повертає значення |
boolean remove(Object key, Object value) |
Видаляє пару, якщо вона присутня |
boolean replace(K key, V oldValue, V newValue) |
Замінює значення на нове, якщо пара присутня |
V replace(K key, V value) |
Замінює значення; якщо ключ є, повертає старе значення |
V compute(K key, BiFunction<?& super K, super V, ? extends V> remappingFunction)
|
Викликає функцію для побудови нового значення. Вводиться нова пара, видаляється пара, яка існувала раніше, і повертається нове значення |
V computeIfPresent(K key, BiFunction<? super K, ? super V,
? extends V> remappingFunction) |
Якщо присутній вказаний ключ, для створення нового значення викликається задана функція і нове значення замінює колишнє. |
V computeIfAbsent(K key, Function<? super K,
? extends V> mappingFunction) |
Повертає значення за ключем. Якщо ключ відсутній, додається нова пара, значення обчислюється за функцією |
V merge(K key, V value, BiFunction<? super V, ? super V,
? extends V> remappingFunction) |
Якщо ключ відсутній, то вводиться нова пара і повертається значення v. В іншому випадку
задана функція повертає нове значення, виходячи з колишнього значення і ключ оновлюється для доступу до
цього значення, а потім воно повертається
|
void forEach(BiConsumer<? super K, ? super V>
action) |
Виконує задану дію (action) над кожним елементом |
Наведений нижче приклад демонструє використання деяких із зазначених методів:
package ua.inf.iwanoff.java.fourth;
import java.util.HashMap;
import java.util.Map;
public class MapDemo {
static void print(Integer i, String s) {
System.out.printf("%3d %10s %n", i, s);
}
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(7, "seven");
map.forEach(MapDemo::print); // порядкове виведення
System.out.println(map.putIfAbsent(7, "eight")); // seven
System.out.println(map.putIfAbsent(8, "eight")); // null
System.out.println(map.getOrDefault(2, "zero")); // two
System.out.println(map.getOrDefault(3, "zero")); // zero
map.replaceAll((i, s) -> i > 1 ? s.toUpperCase() : s);
System.out.println(map); // {1=one, 2=TWO, 7=SEVEN, 8=EIGHT}
map.compute(7, (i, s) -> s.toLowerCase());
System.out.println(map); // {1=one, 2=TWO, 7=seven, 8=EIGHT}
map.computeIfAbsent(2, (i) -> i + "");
System.out.println(map); // нічого не змінилося
map.computeIfAbsent(4, (i) -> i + "");
System.out.println(map); // {1=one, 2=TWO, 4=4, 7=seven, 8=EIGHT}
map.computeIfPresent(5, (i, s) -> s.toLowerCase());
System.out.println(map); // нічого не змінилося
map.computeIfPresent(2, (i, s) -> s.toLowerCase());
System.out.println(map); // {1=one, 2=two, 4=4, 7=seven, 8=EIGHT}
// Уводиться нова пара:
map.merge(9, "nine", (value, newValue) -> value.concat(newValue));
System.out.println(map.get(9)); // nine
// Текст зшивається з попереднім:
map.merge(9, " as well", (value, newValue) -> value.concat(newValue));
System.out.println(map.get(9)); // nine as well
}
}
2.7 Внутрішня організація множин та асоціативних контейнерів
2.7.1 Реалізація множин та асоціативних контейнерів з використанням хешування
Для зберігання даних в HashSet і HashMap використовують так зване хешування. Хешування
(hashing) – це процес отримання з даних про об'єкт унікального коду з використанням деякого формального
алгоритму. У широкому сенсі результатом є послідовність біт фіксованої довжини, в окремому випадку –
просто ціле число. Це перетворення здійснює так звана хеш-функція, або функція хешування. Функція
хешування повинна відповідати такій вимозі: хеш-функція повинна повертати однаковий хеш-код кожного разу, коли
вона застосована до однакових або рівних об'єктів.
Всі об'єкти в Java успадковують стандартну реалізацію hashCode() функції, описаної в класі Object.
Ця функція повертає хеш-код, отриманий шляхом конвертації внутрішньої адреси об'єкта в число, що забезпечує
створення унікального коду для кожного окремого об'єкта.
Конкретні стандартні класи реалізують свої хеш-функції. Наприклад, для рядків значення хеш-функції обчислюється за формулою:
s[0]*31n-1 + s[1]*31n-2 + ... + s[n-1]
Тут s[0], s[1] і т.д. – коди відповідних символів.
Контейнери, побудовані з використанням хешування, не гарантують певного порядку зберігання елементів, проте забезпечують відносно високу ефективність пошуку, додавання і зберігання елементів.
Організація зберігання даних в класах HashSet і HashMap аналогічна. Розглянемо
організацію представлення даних на прикладі контейнера HashMap. Вкладений клас Entry
представляє пару ключ-значення:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
// ...Далі реалізований конструктор і низка допоміжних методів
}
Об'єкти цього класу зберігаються в масиві. Від початку масив розрахований на зберігання 16 елементів, але потім
його розміри можуть змінюватися. Елементи цього масиву іменуються кошиками, оскільки як вони зберігають
посилання на списки елементів (поле next). Під час додавання нової пари ключ-значення, за хеш-кодом
ключа обчислюється номер кошика (номер комірки масиву), в яку потрапить новий елемент. При цьому здійснюється
проєкція значення хеш-коду на масив з урахуванням його реальних розмірів. Якщо кошик порожній, то в ньому
зберігається посилання на доданий елемент, якщо ж там уже є елемент, то відбувається послідовний перехід за
посиланнями по елементах ланцюжка в пошуках останнього елемента, в якому записується посилання на доданий
елемент. Якщо в списку був знайдений елемент з таким же ключем, то значення замінюється.
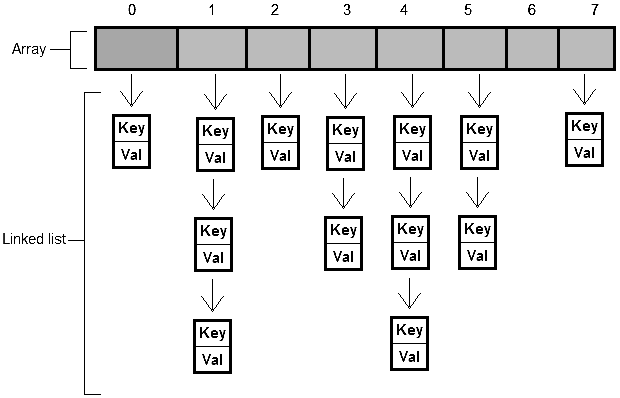
Ефективність операцій додавання, пошуку і видалення залежить від реалізації хеш-функції. Якщо вона видає постійне значення, контейнер перетворюється у зв'язаний список з низькою ефективністю.
2.7.2 Реалізація контейнерів на базі бінарних дерев
Бінарне дерево являє собою деревоподібну структуру даних (граф без циклів), в якій кожна вершина (вузол) має не більше двох нащадків (спадкоємців). Їх називають відповідно лівим і правим спадкоємцем. Своєю чергою, вони можуть виступати як вершини піддерев. Можна говорити про ліве та праве піддерево.
Бінарне дерево може бути використано для упорядкованого за певною ознакою зберігання об'єктів (впорядкування за ключем). У цьому випадку говорять про так зване бінарне дерево пошуку, що задовольняє таким правилам:
- ліве і праве піддерева також є бінарними деревами пошуку;
- в усіх вузлів лівого піддерева деякого вузла значення ключів менше, ніж значення ключа в цього вузла;
- в усіх вузлів правого піддерева того ж вузла значення ключів не менше, ніж значення ключа в цього вузла.
Зазвичай для бінарних дерев пошуку реалізують такі основні операції:
- додавання елемента
- отримання (пошук) елемента
- видалення елемента (вузла)
- обхід дерева
Бінарне дерево має назву ідеально збалансованого, якщо для кожної його вершини кількість вершин в лівому і правому піддереві розрізняються не більше ніж на 1. У незбалансованого дерева це правило не дотримується. Найпростіша реалізація дерева дає незбалансоване дерево. Залежно від порядку додавання елементів дерево може бути збалансованим або зовсім незбалансованим. Припустимо, бінарне дерево зберігає цілі значення. Якщо числа від 1 до 7 додавати в певному порядку (наприклад, 4, 2, 3, 1, 6, 7, 5), може вийти ідеально збалансоване дерево:
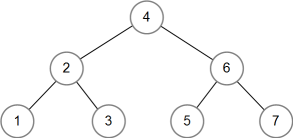
Якщо числа додавати в порядку зростання, буде створено сильно незбалансоване дерево:
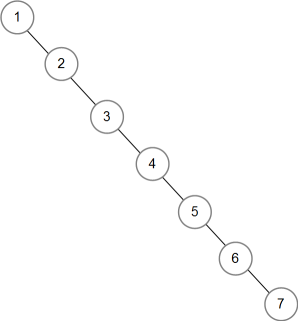
Можна казати про різний степінь збалансованості. Незбалансованість знижує продуктивність під час пошуку елемента. Разом з тим, створення ідеально збалансованих дерев обумовлює обчислювальні труднощі під час додавання і видалення. У реальній практиці найчастіше використовують частково збалансовані дерева.
Так зване червоно-чорне дерево – це бінарне дерево пошуку, яке автоматично підтримує певний баланс. Це дозволяє ефективно реалізувати основні операції (додавання, пошук і видалення). Кожному вузлу дерева ставиться у відповідність колір – червоний або чорний. До кожного вузла додаються фіктивні листові вузли, що не містять даних. Також накладаються додаткові вимоги:
- Корінь дерева повинен бути чорним
- Всі листові вузли – чорні
- Обидва нащадки кожного червоного вузла – чорні
- Кожен простий шлях від цього вузла до будь-якого листового вузла, що є його нащадком, містить однакове число чорних вузлів
Наприклад, можна отримати таке червоно-чорне дерево (з сайту en.wikipedia.org):
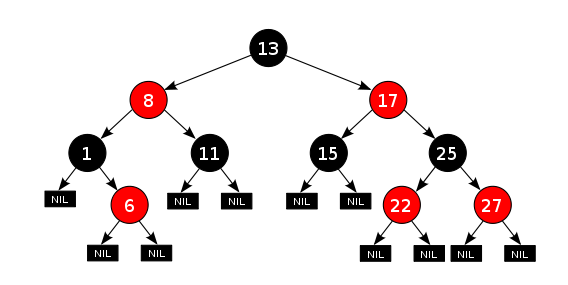
Під час додавання нового вузла (завжди червоного) іноді доводиться перефарбовувати дерево і "обертати"
його. Додавання вершин з урахуванням обмежень і "обертання" з перенесенням вузлів робить дерево
самозбалансованим. Червоно-чорні дерева використовують для побудови контейнерів TreeSet і TreeMap.
2.8 Створення власних контейнерів
Попри велику кількість стандартних контейнерних класів, іноді виникає потреба в створенні власних контейнерів. Це можуть бути, наприклад, складні дерева, більш гнучкі списки, спеціалізовані колекції елементів і т.д.
У деяких випадках необхідно тільки обходити елементи деякої послідовності за допомогою альтернативної форми
циклу for. Для цього достатньо реалізувати інтерфейс Iterable<>. Він
вимагає реалізації функції, що повертає ітератор. Найчастіше для реалізації ітератора створюють внутрішній
нестатичний клас. У наведеному нижче прикладі створюється клас "речення" з ітератором, який
переміщається за окремими словами. Програма виводить слова введеного речення в окремих рядках:
package ua.inf.iwanoff.java.fourth;
import java.util.Iterator;
import java.util.Scanner;
import java.util.StringTokenizer;
public class Sentence implements Iterable<String> {
private String text;
public Sentence(String text) {
this.text = text;
}
private class WordsIterator implements Iterator<String> {
StringTokenizer st = new StringTokenizer(text);
@Override
public boolean hasNext() {
return st.hasMoreTokens();
}
@Override
public String next() {
return st.nextToken();
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
public Iterator<String> iterator() {
return new WordsIterator();
}
public static void main(String[] args) {
String text = new Scanner(System.in).nextLine();
Sentence sentence = new Sentence(text);
for (String word : sentence) {
System.out.println(word);
}
}
}
У більшості випадків для створення ітераторів необхідно описати так званий курсор – змінну, яка
посилається на поточний елемент послідовності. У цьому випадку реалізація методу next() передбачає
переміщення курсора й повернення посилання на поточний елемент. Наприклад:
public class SomeArray<E> implements Iterable<E> {
private E[] arr;
...
private class InnerIterator implements Iterator<E> {
int cursor = -1;
@Override
public boolean hasNext() {
return cursor < arr.length – 1;
}
@SuppressWarnings("unchecked")
@Override
public E next() {
return arr[++cursor];
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
@Override
public Iterator<E> iterator() {
return new InnerIterator();
}
...
}
Для створення повноцінних власних контейнерів найкраще скористатися наявними абстрактними класами. Це AbstractCollection<E>,
AbstractList<E>, AbstractMap<K,V>, AbstractQueue<E>,
AbstractSet<E>, а також деякі абстрактні допоміжні класи. Наприклад, для того, щоб створити
власний список (тільки для читання), формально досить перекрити два абстрактних методи –
get() і size(). Під час роботи зі списками тільки для читання методи типу
add(), set(), remove() та інші, призначені для зміни списку, генерують
виняток UnsupportedOperationException. У наведеному нижче прикладі створюється найпростіший список
(тільки для читання):
package ua.inf.iwanoff.java.fourth;
import java.util.AbstractList;
public class MyList extends AbstractList<String> {
String[] arr = { "one", "two", "three" };
@Override
public String get(int index) {
return arr[index];
}
@Override
public int size() {
return arr.length;
}
public static void main(String[] args) {
MyList list = new MyList();
for (String elem : list) {
System.out.println(elem); {
}
System.out.println(list.subList(0, 2)); // [one, two]
System.out.println(list.indexOf("two")); // 1
list.add("four"); // Виняток "UnsupportedOperationException"
}
}
Для того, щоб реалізувати контейнер для читання і запису, необхідно перекрити відповідні методи. У прикладі 3.9 реалізований відповідний контейнер.
3 Приклади програм
3.1 Опис та використання переліку
Припустимо, необхідно створити перелік, який описує дні тижня. Раніше був наведений приклад такого переліку. До
нього слід додати функцію отримання наступного дня, при чому після суботи знов повинна бути неділя тощо. Крім
того, необхідна функція перевірки, чи відноситься день до вікенду. Під час виведення також необхідно отримувати
номер дня (0 – неділя, 1 – понеділок тощо. д.). У функції main(), починаючи з понеділка необхідно
пройтися по днях тижня, вивести дані про день, а також перевірити, чи це вікенд. Програма матиме такий вигляд:
package ua.inf.iwanoff.java.fourth;
enum DayOfWeek {
SUNDAY,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY;
@Override
public String toString() {
return name() + " " + ordinal();
}
DayOfWeek next() {
DayOfWeek day = values()[(ordinal() + 1) % values().length];
return day;
}
boolean isWeekend() {
switch (this) {
case SATURDAY:
case SUNDAY:
return true;
default:
return false;
}
}
}
public class EnumTest {
public static void main(String[] args) {
DayOfWeek d = DayOfWeek.MONDAY;
for (int i = 0; i < 7; i++) {
d = d.next();
System.out.println(d + " " + d.isWeekend());
}
}
}
Як і в інших випадках, формою виведення даних керує перекритий метод toString().
3.2 Узагальнена функція пошуку певного елемента
Припустимо, необхідно реалізувати статичну узагальнену функцію отримання індексу першого входження елемента з визначеним значенням. Функція повинна повертати індекс цього елемента або -1, якщо елемент відсутній. Клас із необхідною функцією матиме такий вигляд:
package ua.inf.iwanoff.java.fourth;
public class ElementFinder {
public static <E>int indexOf(E[] arr, E elem) {
for (int i = 0; i < arr.length; i++) {
if (arr[i].equals(elem)) {
return i;
}
}
return -1;
}
public static void main(String[] args) {
Integer[] a = {1, 2, 11, 4, 5};
System.out.println(indexOf(a, 11)); // 2
System.out.println(indexOf(a, 12)); // -1
String[] b = {"one", "two"};
System.out.println(indexOf(b, "one")); // 0
}
}
Для порівняння значень об'єктів слід використовувати метод equals() замість ==.
3.3 Сума елементів типу Double
Наступна програма читає дійсні числа, які вводить користувач, заносить їх у список та знаходить суму.
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class SumOfElements {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
List<Double> a = new ArrayList<>();
double d = 1; // початкове значення не повинне бути 0
while (d != 0) {
d = scanner.nextDouble();
a.add(d);
}
double sum = 0;
for (double x : a) { // неявний ітератор
sum += x;
}
System.out.println("Сума: " + sum);
}
}
Читання чисел з клавіатури здійснюється доти, доки користувач не введе значення 0.
3.4 Індекс максимального елемента
Наступна програма знаходить номер максимального елемента в списку цілих чисел. Для заповнення списку можна
використати масив з початковими значеннями елементів. Масив неявно створюється під час виконання функції asList().
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class MaxElement {
public static void main(String[] args) {
List<Integer> a = Arrays.asList(2, 3, -7, 8, 11, 0);
int indexOfMax = 0;
for (int i = 1; i < a.size(); i++) {
if (a.get(i) > a.get(indexOfMax)) {
indexOfMax = i;
}
}
System.out.println(indexOfMax + " " + a.get(indexOfMax));
}
}
Оскільки шукаємо індекс, не доцільно застосовувати ітератор.
3.5 Дані про країни в асоціативному масиві
Дані про країни (назва і територія) можна зберігати в асоціативному масиві. Виведення здійснюється за алфавітом країн:
package ua.inf.iwanoff.java.fourth;
import java.util.Map;
import java.util.SortedMap;
import java.util.TreeMap;
public class Countries {
public static void main(String[] args) {
SortedMap<String, Double> countries = new TreeMap<>();
countries.put("Україна", 603700.0);
countries.put("Німеччина", 357021.0);
countries.put("Франція", 547030.0);
for (Map.Entry<?, ?> entry : countries.entrySet())
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
3.6 Літери речення в алфавітному порядку
У наведеному нижче прикладі вводиться речення і виводяться всі різні літери речення (за винятком роздільників) в алфавітному порядку:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class Sentence {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// Функція nextLine() читає рядок до кінця:
String sentence = scanner.nextLine();
// Створюємо множину роздільників:
Set<Character> delimiters = new HashSet<Character>(
Arrays.asList(' ', '.', ',', ':', ';', '?', '!', '-', '(', ')', '\"'));
// Створюємо множину літер:
Set<Character> letters = new TreeSet<Character>();
// Додаємо всі літери крім роздільників:
for (int i = 0; i < sentence.length(); i++) {
if (!delimiters.contains(sentence.charAt(i))) {
letters.add(sentence.charAt(i));
}
}
System.out.println(letters);
}
}
3.7 Добуток чисел, що вводяться
У наведеному нижче прикладі вводяться цілі числа, виводяться за зменшенням, а також обчислюється їх добуток. Введення завершується нулем:
package ua.inf.iwanoff.java.fourth;
import java.util.*;
public class Product {
public static void main(String[] args) {
Queue<Integer> queue = new PriorityQueue<>(100, new Comparator<Integer>() {
@Override
public int compare(Integer i1, Integer i2) {
return -Double.compare(i1, i2);
}
});
Scanner scanner = new Scanner(System.in);
Integer k;
do {
k = scanner.nextInt();
if (k != 0) {
queue.add(k);
}
}
while (k != 0);
int p = 1;
while ((k = queue.poll()) != null) {
p *= k;
System.out.print(k + " ");
}
System.out.println();
System.out.println(p);
}
}
3.8 Створення однобічно зв'язаного списку
У наведеному нижче прикладі створюється і заповнюється однобічно зв'язаний список:
package ua.inf.iwanoff.java.fourth;
public class SinglyLinkedList<E> {
private class Node {
E data;
Node next;
Node(E data, Node next) {
this.data = data;
this.next = next;
}
}
private Node first = null;
private Node last = null;
private int count = 0;
public void add(E elem) {
Node newNode = new Node(elem, null);
if (last == null) {
first = newNode;
}
else {
last.next = newNode;
}
last = newNode;
count++;
}
public void removeFirstOccurrence(E value) {
// Окремо перевіряємо перший елемент
if (first != null && first.data.equals(value)) {
first = first.next;
count--;
}
else {
Node link = first;
while (link.next != null) {
if (link.next.data.equals(value)) {
link.next = link.next.next;
count--;
}
if (link.next == null) {
last = link;
break; // видалили останній елемент
}
link = link.next;
}
}
}
public final int size() {
return count;
}
@Override
public String toString() {
String s = "size = " + size() + "\n[";
Node link = first;
while (link != null) {
s += link.data;
link = link.next;
if (link != null) {
s += ", ";
}
}
s += "]\n";
return s;
}
public static void main(String[] args) {
SinglyLinkedList<Integer> list = new SinglyLinkedList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
System.out.println(list);
// Видаляємо середній елемент:
list.removeFirstOccurrence(3);
System.out.println(list);
// Видаляємо перший елемент:
list.removeFirstOccurrence(1);
System.out.println(list);
// Видаляємо останній елемент:
list.removeFirstOccurrence(4);
System.out.println(list);
}
}
3.9 Створення бінарного дерева
У наведеному нижче прикладі створюється і заповнюється звичайне (незбалансоване) бінарне дерево, що містить пари ціле / рядок:
package ua.inf.iwanoff.java.fourth;
public class BinaryTree {
// Клас для представлення вузла
public static class Node {
int key;
String value;
Node leftChild;
Node rightChild;
Node(int key, String name) {
this.key = key;
this.value = name;
}
@Override
public String toString() {
return "Key: " + key + " Value:" + value;
}
}
private Node root;
public void addNode(int key, String value) {
// Створюємо новий вузол:
Node newNode = new Node(key, value);
if (root == null) { // перший доданий вузол
root = newNode;
}
else {
// Починаємо обхід:
Node currentNode = root;
Node parent;
while (true) {
parent = currentNode;
// Перевіряємо ключі:
if (key < currentNode.key) {
currentNode = currentNode.leftChild;
if (currentNode == null) {
// Розміщуємо вузол в потрібному місці:
parent.leftChild = newNode;
return;
}
}
else {
currentNode = currentNode.rightChild;
if (currentNode == null) {
// Розміщуємо вузол в потрібному місці:
parent.rightChild = newNode;
return;
}
}
}
}
}
// Обхід вузлів в порядку зростання ключів
public void traverseTree(Node currentNode) {
if (currentNode != null) {
traverseTree(currentNode.leftChild);
System.out.println(currentNode);
traverseTree(currentNode.rightChild);
}
}
public void traverseTree() {
traverseTree(root);
}
// Пошук вузла за ключем
public Node findNode(int key) {
Node focusNode = root;
while (focusNode.key != key) {
if (key < focusNode.key) {
focusNode = focusNode.leftChild;
}
else {
focusNode = focusNode.rightChild;
}
// Не знайшли:
if (focusNode == null) {
return null;
}
}
return focusNode;
}
// Тест:
public static void main(String[] args) {
BinaryTree continents = new BinaryTree();
continents.addNode(1, "Європа");
continents.addNode(3, "Африка");
continents.addNode(5, "Австралія");
continents.addNode(4, "Америка");
continents.addNode(2, "Азія");
continents.addNode(6, "Антарктида");
continents.traverseTree();
System.out.println("\nКонтинент з ключем 4:");
System.out.println(continents.findNode(4));
}
}
3.10 Створення власного контейнера на базі списку ArrayList
У наведеному нижче прикладі реалізований клас для представлення масиву, індексація якого починається з 1.
Необхідно перевизначити всі методи, пов'язані з індексом. Всередині можна використовувати ArrayList:
package ua.inf.iwanoff.java.fourth;
import java.util.AbstractList;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
@SuppressWarnings("unchecked")
public class ArrayFromOne<E> extends AbstractList<E> {
ArrayList<Object> arr = new ArrayList<>();
@Override
public E get(int index) {
return (E)arr.get(index – 1);
}
@Override
public int size() {
return arr.size();
}
@Override
public void add(int index, E element) {
arr.add(index – 1, element);
}
@Override
public boolean add(E e) {
return arr.add(e);
}
@Override
public E set(int index, E element) {
return (E)arr.set(index – 1, element);
}
@Override
public E remove(int index) {
return (E)arr.remove(index – 1);
}
@Override
public int indexOf(Object o) {
return arr.indexOf(o) + 1;
}
@Override
public int lastIndexOf(Object o) {
return arr.lastIndexOf(o) + 1;
}
@Override
public Iterator<E> iterator() {
return (Iterator<E>)arr.iterator();
}
public static void main(String[] args) {
ArrayFromOne<Integer> a = new ArrayFromOne<>();
a.add(1);
a.add(2);
System.out.println(a.get(1) + " " + a.get(2)); // 1 2
System.out.println(a.indexOf(2)); // 2
a.set(1, 3);
for (Integer k : a) {
System.out.print(k + " "); // 3 2
}
System.out.println();
a.remove(2);
System.out.println(a); // [3]
a.addAll(Arrays.asList(new Integer[]{ 4, 5 }));
System.out.println(a.get(3)); // 5
}
}
Анотація @SuppressWarnings("unchecked") перед класом потрібна для пригнічення
попереджень, пов'язаних з явним приведенням типів.
3.11 Зберігання даних про переписи у списку і множині
Припустимо, необхідно створити класи для роботи з переписами. Перший з них зберігатиме дані у за допомогою списку,
другий за допомогою множини. Можна додати такі класи до попередньо створеної ієрархії. Перший клас зберігатиме дані в
списку. Для сортування за населенням доцільно використати статичний метод sort() класу
Collections.
Для сортування за алфавітом коментарів можна скористатися методом sort() інтерфейсу
List. Код класу буде таким:
package ua.inf.iwanoff.java.fourth;
import ua.inf.iwanoff.java.second.Census;
import ua.inf.iwanoff.java.second.AbstractCountry;
import java.util.*;
/**
* Клас для представлення країни, в якій здійснюється перепис населення.
* Дані про переписи представлені списком
*/
public class CountryWithList extends AbstractCountry {
private List<Census> list = new ArrayList<>();
/**
* Повертає посилання на перепис населення,
* визачений його індексом в послідовності
* @param i номер (індекс) перепису
* @return посилання на перепис населення
*/
@Override
public Census getCensus(int i) {
return list.get(i);
}
/**
* Встановлює посилання на новий перепис всередині позиції послідовностей
* за вказаним індексом.
* @param i номер (індекс) позиції в послідовності
* @param census посилання на новий перепис
*/
@Override
public void setCensus(int i, Census census) {
list.set(i, census);
}
/**
* Додає посилання на новий перепис в кінець послідовності
* @param census посилання на новий перепис
* @return {@code true}, якщо посилання вдалося додати
* {@code false} в протилежному випадку
*/
@Override
public boolean addCensus(Census census) {
if (list.contains(census)) {
return false;
}
return list.add(census);
}
/**
* Створює новий перепис та додає посилання на нього в кінець послідовності.
* @param year рік перепису
* @param population кількість населення
* @param comments текст коментаря
* @return {@code true}, якщо посилання вдалося додати
* {@code false} в протилежному випадку
*/
@Override
public boolean addCensus(int year, int population, String comments) {
return addCensus(new Census(year, population, comments));
}
/**
* Повертає кількість переписів у послідовності
* @return кількість переписів
*/
@Override
public int censusesCount() {
return list.size();
}
/**
* Очищує послідовність переписів
*/
@Override
public void clearCensuses() {
list.clear();
}
/**
* Здійснює сортування послідовності переписів за кількістю населення
*/
@Override
public void sortByPopulation() {
Collections.sort(list);
}
/**
* Здійснює сортування послідовності переписів за алфавітом коментарів
*/
@Override
public void sortByComments() {
list.sort(Comparator.comparing(Census::getComments));
}
/**
* Переписує дані з масиву переписів у послідовність
* @param censuses довільний масив переписів
*/
@Override
public void setCensuses(Census[] censuses) {
list = new ArrayList<>(Arrays.asList(censuses));
}
/**
* Повертає масив переписів з послідовності
* @return сформаваний масив посилань на переписи
*/
@Override public Census[] getCensuses() {
return list.toArray(new Census[0]);
}
/**
* Демонстрація роботи програми
* @param args аргументи командного рядка (не використовуються)
*/
public static void main(String[] args) {
new CountryWithList().createCountry().testCountry();
}
}
Тепер можна створити клас, який забезпечує зберігання даних у множині. Оскільки множина одразу впорядкована за певною ознакою і здійснити її сортування немає можливості, для отримання відсортованих послідовностей можна створювати різні варіанти наборів даних.
Від початку переписи повинні бути розташовані за зростанням року. Код класу CountryWithSet буде
таким:
package ua.inf.iwanoff.java.fourth;
import ua.inf.iwanoff.java.second.Census;
import ua.inf.iwanoff.java.second.AbstractCountry;
import java.util.Arrays;
import java.util.Comparator;
import java.util.SortedSet;
import java.util.TreeSet;
/**
* Клас для представлення країни, в якій здійснюється перепис населення.
* Дані про переписи представлені множиною
*/
public class CountryWithSet extends AbstractCountry {
private SortedSet<Census> set = new TreeSet<>(Comparator.comparing(Census::getYear));
/**
* Повертає посилання на перепис населення,
* визачений його індексом в послідовності
* @param i номер (індекс) перепису
* @return посилання на перепис населення
*/
@Override
public Census getCensus(int i) {
return set.toArray(new Census[0])[i];
}
/**
* Встановлює посилання на новий перепис всередині позиції послідовностей
* за вказаним індексом.
* @param i номер (індекс) позиції в послідовності
* @param census посилання на новий перепис
*/
@Override
public void setCensus(int i, Census census) {
Census oldCensus = getCensus(i);
set.remove(oldCensus);
set.add(census);
}
/**
* Додає посилання на новий перепис в кінець послідовності
* @param census посилання на новий перепис
* @return {@code true}, якщо посилання вдалося додати
* {@code false} в протилежному випадку
*/
@Override
public boolean addCensus(Census census) {
return set.add(census);
}
/**
* Створює новий перепис та додає посилання на нього в кінець послідовності.
* @param year рік перепису
* @param population кількість населення
* @param comments текст коментаря
* @return {@code true}, якщо посилання вдалося додати
* {@code false} в протилежному випадку
*/
@Override
public boolean addCensus(int year, int population, String comments) {
return set.add(new Census(year, population, comments));
}
/**
* Повертає кількість переписів у послідовності
* @return кількість переписів
*/
@Override
public int censusesCount() {
return set.size();
}
/**
* Очищує послідовність переписів
*/
@Override
public void clearCensuses() {
set.clear();
}
/**
* Здійснює сортування послідовності переписів за кількістю населення
*/
@Override
public void sortByPopulation() {
SortedSet<Census> newSet = new TreeSet<>();
newSet.addAll(set);
set = newSet;
}
/**
* Здійснює сортування послідовності переписів за алфавітом коментарів
*/
@Override
public void sortByComments() {
SortedSet<Census> newSet = new TreeSet<>(Comparator.comparing(Census::getComments));
newSet.addAll(set);
set = newSet;
}
/**
* Переписує дані з масиву переписів у послідовність
* @param censuses довільний масив переписів
*/
@Override
public void setCensuses(Census[] censuses) {
set = new TreeSet<>(Comparator.comparing(Census::getYear));
set.addAll(Arrays.asList(censuses));
}
/**
* Повертає масив переписів з послідовності
* @return сформаваний масив посилань на переписи
*/
@Override
public Census[] getCensuses() {
return set.toArray(new Census[0]);
}
/**
* Демонстрація роботи програми
* @param args аргументи командного рядка (не використовуються)
*/
public static void main(String[] args) {
new CountryWithSet().createCountry().testCountry();
}
}
Результати роботи програм повинні бути ідентичними.
4 Вправи для контролю
- Створити перелік "День тижня". Додати методи отримання дня "позавчора" та "післязавтра".
Протестувати перелік у функції
main()тестового класу. - Створити перелік "Сезон". Описати метод отримання попереднього та наступного сезону. Протестувати
перелік у функції
main()тестового класу. - Створити перелік "Континент". Перевантажити метод
toString()так, щоб він показував назву континенту українською (російською) мовою. Протестувати перелік у функціїmain()тестового класу. - Реалізувати статичну узагальнену функцію отримання індексу останнього входження елемента з визначеним значенням. Здійснити тестування функції на двох масивах різних типів.
- Реалізувати статичну узагальнену функцію заміни порядку елементів на протилежний. Здійснити тестування функції на двох масивах різних типів.
- Реалізувати статичну узагальнену функцію визначення кількості разів входження певного елемента у масив. Здійснити тестування функції на двох масивах різних типів.
- Реалізувати статичну узагальнену функцію циклічного зсуву масиву на задану кількість елементів. Здійснити тестування функції на двох масивах різних типів.
- Прочитати з клавіатури значення елементів списку цілих чисел. Знайти добуток елементів.
- Проініціалізувати список дійсних чисел масивом зі списком початкових значень. Знайти суму додатних елементів.
- Проініціалізувати список цілих чисел масивом зі списком початкових значень. Знайти добуток ненульових елементів.
- Проініціалізувати список цілих чисел масивом зі списком початкових значень. Створити новий список, складений з парних елементів вихідного списку.
- Проініціалізувати список дійсних чисел масивом зі списком початкових значень. Створити новий список, складений з додатних елементів вихідного списку.
- Проініціалізувати список рядків масивом зі списком початкових значень. Знайти та вивести рядок з найбільшою довжиною.
- Проініціалізувати список рядків масивом зі списком початкових значень. Знайти та вивести індекс рядка з найменшою довжиною.
- Увести кількість елементів майбутньої множини цілих чисел та діапазон чисел. Сформувати цю множину з випадкових значень. Вивести елементи множини, відсортовані за збільшенням.
- Увести кількість елементів майбутньої множини дійсних чисел та діапазон чисел. Сформувати цю множину з випадкових значень. Вивести елементи множини за зменшенням.
- Заповнити множину цілих випадковими додатними парними значеннями (не більше визначеного числа). Вивести результат.
- Увести слово та вивести всі різні літери слова в алфавітному порядку.
- Увести речення та обчислити кількість різних літер, з яких речення складається. Не враховувати пропусків та розділових знаків.
- Увести речення та обчислити кількість різних слів у реченні.
- Проініціалізувати список цілих чисел масивом зі списком початкових значень. Знайти суму максимального і
мінімального елементів. Застосувати функції класу
Collections. - Проініціалізувати список рядків масивом зі списком початкових значень. Змінити порядок елементів на
зворотний. Застосувати функцію класу
Collections. - Створити функцію, яка обчислює квадратний корінь, якщо це можливо і повертає об'єкт типу
OptionalDouble.
5 Контрольні запитання
- Для чого можуть бути застосовані переліки?
- Для чого визначається конструктор переліку?
- Як у циклі отримати усі константи, описані в переліку?
- Які проблеми пов'язані зі створенням узагальнених контейнерів?
- У яких випадках доцільно створювати узагальнені класи?
- Що таке параметризований тип?
- Чим узагальнення відрізняються від шаблонів C++?
- Для чого використовують узагальнені функції?
- Чи можна створювати об'єкти узагальнених типів?
- Чи можна створювати масиви узагальнених типів?
- Чому в контейнерному класі не можна зберігати цілі й дійсні числа безпосередньо, а можна тільки посилання?
- Як накласти обмеження на параметр узагальнення і які можливості це надає?
- Для чого в описі параметрів використовують маски (wildcards)?
- Чи можна використовувати маски під час створення локальних змінних?
- Для чого використовують клас
Optional? - Чи можна використовувати клас
Optionalз примітивними типами? - Що таке колекція?
- Які базові інтерфейси описані в пакеті
java.util? - Які контейнери вважають застарілими?
- Чому в колекції не можна зберігати цілі й дійсні числа безпосередньо, а можна тільки посилання?
- Як з масиву отримати список?
- Як зберегти у списку цілі й дійсні значення?
- У чому перевага опису посилання на інтерфейс контейнера (наприклад,
List) у порівнянні з описом посилання на клас, що реалізує контейнер (наприклад,ArrayList)? - У чому перевага використання ітераторів у порівнянні з індексами елементів контейнера?
- Коли доцільніше використовувати
LinkedListу порівнянні зArrayList(і навпаки)? - Яку структуру даних використовують для реалізації
LinkedList? - Які методи інтерфейсу
Queueвикористовують для додавання елементів? - З якою метою методи роботи з чергою реалізовані у двох варіантах – з генерацією винятку і без?
- Для чого використовують клас
PriorityQueue? - Для чого використовують стеки?
- Які є стандартні способи реалізації стека?
- Які алгоритми надає клас
Collections? - Чим множина відрізняється від списку?
- Наведіть приклади використання асоціативних масивів.
- У чому відмінності інтерфейсів
MapтаSortedMap? - Як використовують "кошики" для зберігання даних в хеш-таблиці?
- Що таке бінарне дерево?
- Що таке збалансоване і незбалансоване дерево?
- Що таке червоно-чорне дерево і які у нього переваги?
- Як створити власний контейнер?
- Як реалізувати контейнер тільки для читання?